

버블로 구현한 페이지를 사용하다 보면 속도에 아쉬움을 느낄 때가 많은데요. 오늘은 버블 앱 성능 최적화 팁을 소개해 드리겠습니다.
데이터량이 많아질수록 검색과 필터링 속도가 느려질 수 있어요. 특히 검색 조건이 복잡하거나 데이터 구성이 복잡하면 성능 저하를 유발하기 쉽운데요. 이를 방지하기 위해 검색 단계에서의 데이터 처리 방식을 개선하면 불필요한 로드를 줄이고 더욱 안정적인 사용자 경험을 제공할 수 있습니다.
Bubble을 쓰다 보면, 데이터가 많아질수록 검색과 필터링 속도가 눈에 띄게 저하되는 경우를 자주 접하게 돼요. 특히 OR 조건이 필요한 복합 검색, 여러 Data Type 간의 연관관계, Advanced Filter가 얽힌 상황에서는 퍼포먼스가 급격히 떨어질 수 있습니다.
버블 내부 구현 특성상, “검색자체에서 필터링 · 정렬을 얼마큼 DB에 맡기느냐”, “불필요하게 많은 데이터를 한 번에 가져오지 않느냐”가 성능을 좌우하는 핵심 요인이 됩니다. 이 글에서는 실제 버블 앱 개발 현장에서 자주 겪는 검색 · 필터링 관련 성능 이슈들을 중심으로, 어떻게 하면 DB를 제대로 활용하고 Advanced Filter 사용을 최소화하여 속도를 높일 수 있는지에 대해 정리해보겠습니다. 이 글에서 다룰 주제는 다음과 같습니다.
- 검색에 필터링 · 정렬 로직을 넣는 노하우
- 버블의 자체적인 퍼포먼스 최적화
- 여러 검색을 순차 대신 병렬로 처리할 수 있도록 구축하는 방법
- OR 조건 처리 시 merged with와 sort를 결합해 사용하는 방법
- 필터 순서가 퍼포먼스에 끼치는 영향
- 2개 이상의 Data Type을 다루어야 할때 Advanced Filter 사용을 줄이는 방법
이제부터 각 항목을 하나씩 살펴보면서, 실제로 어떻게 적용하면 좋은지 구체적으로 알아보겠습니다.
버블에서 데이터 요청 최적화를 위한 필터 · 정렬 방식
기본 검색(Search) 자체에 최대한 필터링 · 정렬 로직을 넣는 것이 좋습니다.
이것은 서버에 요청하기 위해 쿼리를 실행할때 필터링 · 정렬 로직을 포함시켜 애초부터 적은 데이터를 불러오는것을 의미합니다.
데이터가 처음부터 적게 로드되도록 하는 것이 핵심입니다. “:filtered”, “:unique”, “:count”, “merged with” 등의 추가 연산을 하기 전에, “Do a Search For” 내부에 필터 조건을 추가시켜 처음 검색 단계에서 검색 범위를 줄이는것이 좋습니다.
정렬도 비슷합니다. 검색 자체에 정렬 조건을 넣으면 데이터베이스에서 정렬을 수행하지만, “Do a Search For”로 데이터를 불러온 뒤 “:filtered”나 다른 연산을 거치고 나서 그 결과를 다시 정렬하면, 어떤 항목이 가장 앞서는지를 판단하기 위해 전체 데이터를 모두 불러와야 합니다.
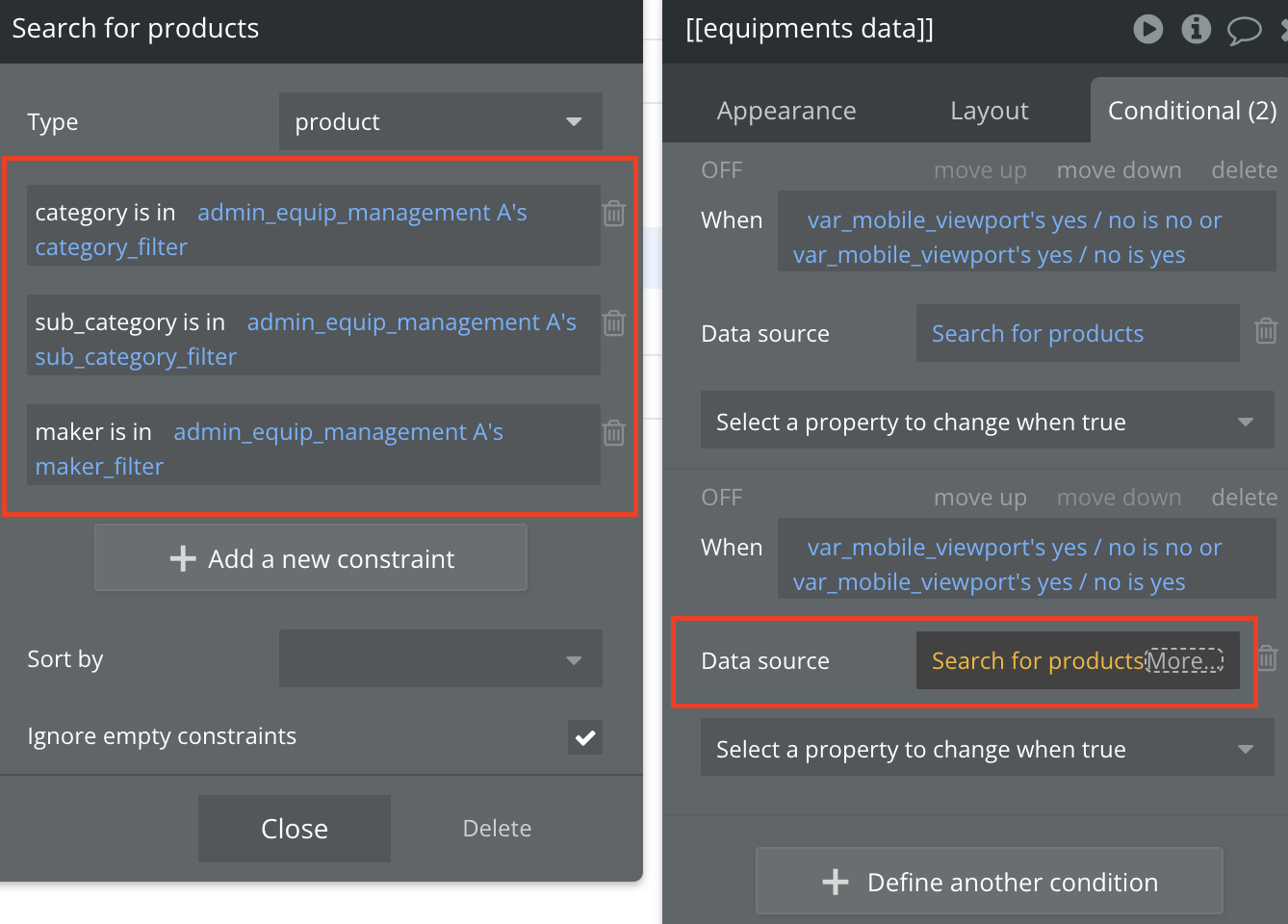
검색에 필터링 로직 포함시켜 적은 데이터를 불러오는 경우
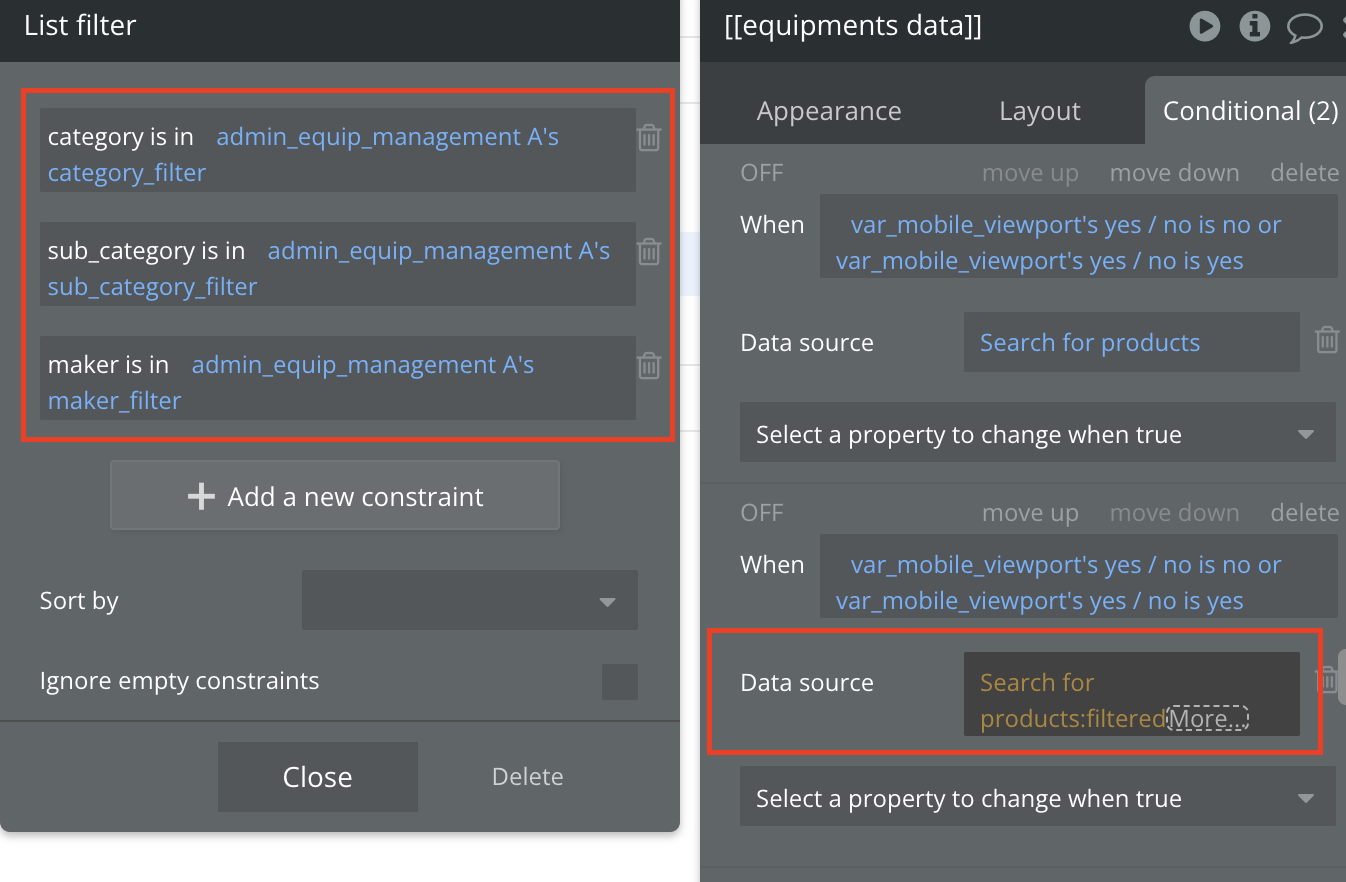
많은 데이터를 불러온 후 필터링 하는 경우
버블 자체적인 퍼포먼스 최적화
Bubble은 필요한 것보다 더 많이 로드하지 않으려고 최적화 되어있는 부분이 있습니다.
이 부분은 버블측에서 계속 개선해나가고 있는 부분입니다. 예를 들어 “Search → :count”처럼 중간에 다른 연산이 없는 경우는 전체 데이터를 불러오지 않고도 데이터베이스에서 직접 개수를 셀 수 있습니다.
예시 1
“Search → :count”가 “Search → :unique → :count”보다 훨씬 빠릅니다.
예시 2
Repeating Group 안에서 검색을 사용할 때, 눈에 보이는 셀을 채우기에 충분한 양의 데이터와 스크롤 가능성을 고려한 약간의 버퍼만 불러옵니다.
하지만, 추가적인 연산(예: 검색 결과에 :filtered를 추가)을 하면, 필터를 통과하는 항목을 찾기 위해 더 많은 데이터를 불러올 수 있습니다. 예를 들어 10개의 셀을 가진 Repeating group이 있고, 필터를 적용한 결과를 만들려면, 10개를 충족하기 위해 100개의 항목을 불러올 수도 있습니다.
버블에서 Data Source를 재사용할때 최적화 방법
동적 데이터를 다른 검색의 제약 조건(Constraint)으로 사용하는 경우, 두 번째 검색은 첫 번째 검색이 끝난 후에야 시작할 수 있습니다.
즉, 첫 번째 검색 결과가 나와야 두 번째 검색의 제약 조건 값을 알 수 있기 때문입니다. 첫 번째 검색이 적은 양의 데이터를 반환한다면 문제가 크지 않지만, 많은 데이터를 반환하는 경우, 이런 식으로 여러 검색이 순차적으로 이어지면 매우 느려질 수 있습니다. 버블은 보통 병렬 처리를 지향하지만, 이 경우에는 한 번에 하나씩만 처리해야 하기 때문입니다.
가능한 한 동시에(병렬로) 처리될 수 있도록 설계해보세요.
https://0ff2478d75ac2476d424d77eb551230c.cdn.bubble.io/f1737092165704x512486446182379100/Screenshot%202025-01-03%20at%204.04.10%20PM.png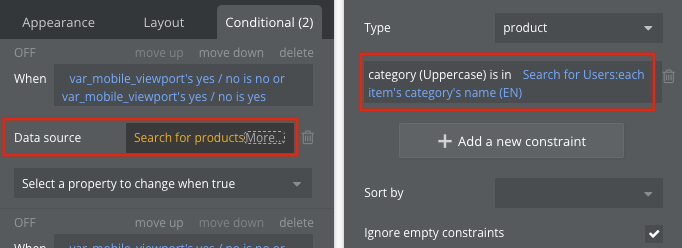
첫번째 검색(Search For User)이 끝날때까지 기다렸다가 두번째 검색(Search For Product)이 시작되는 경우
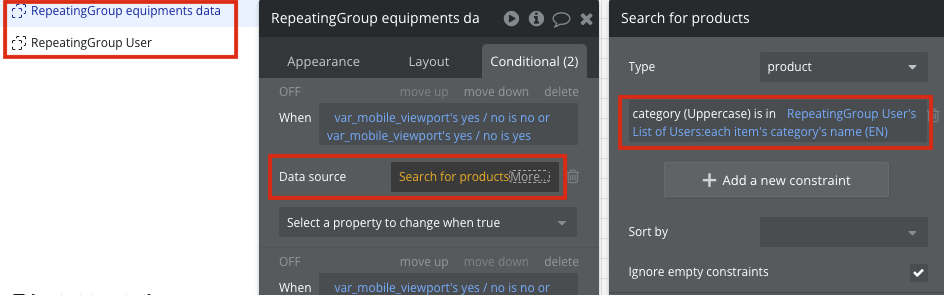
별도의 Repeating Group을 재사용해서 퍼포먼스를 개선합니다.
Merged with와 Advanced filter의 비교
OR 조건이 필요한경우, Advanced filter를 사용하는 것은 좋은 방법은 아닙니다. 그것보다는 merged with를 사용하는것이 퍼포먼스 측면에서 훨씬 좋습니다. 왜 그럴까요? 예시를 통해 알아보겠습니다.
예를들면 검색창이 검색할 수 있는 검색어의 타입이 여러개인 경우에 OR 조건으로 필터 조건을 만들어야 합니다.
두 방식 모두 row 개수는 고정하고 시작합니다.
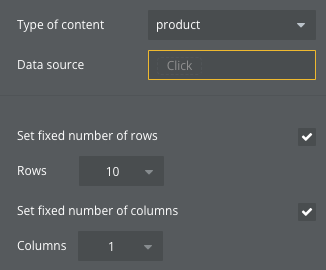
먼저 Advanced filter를 사용하는 방식은 다음과 같습니다.
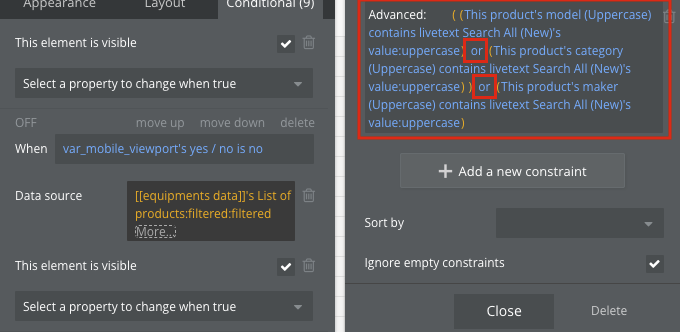
다음은 merge with를 사용하는 방식입니다. 별도의 Repeating Group에서 불러온 데이터를 재사용 해서 합치는것이 좋습니다.
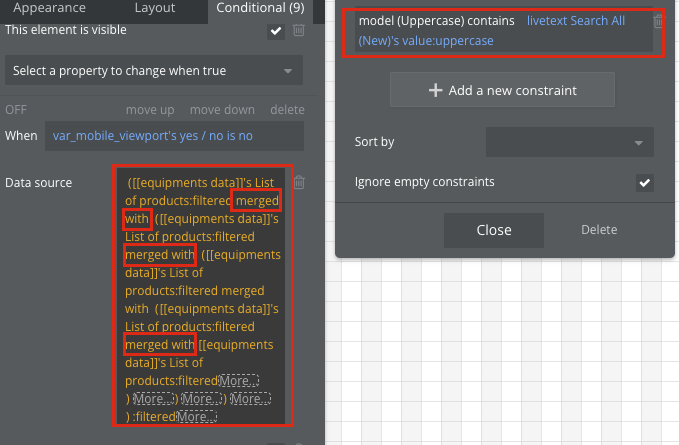
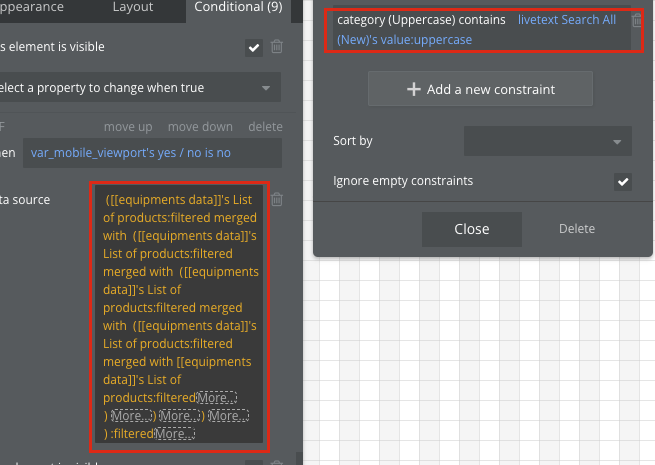
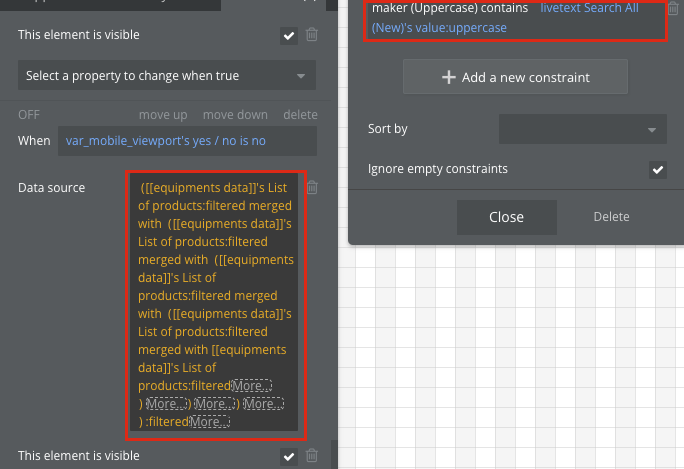
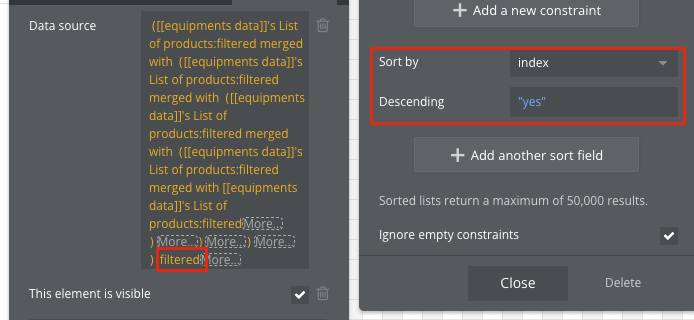
이때, expression의 마지막에 sort를 해주는것이 속도 최적화의 핵심입니다. Sort 조건을 붙여서 데이터를 요청하면 (Do a search for: + :filtered→sort (filter 내부에서 sort)), 인덱싱이 되어 가장 마지막에 있는 데이터도 빠르게 검색이 가능합니다. Sort가 Do a search for 외부에 있음에도 불구하고 최적화 되는것은 버블의 퍼포먼스 최적화의 일환으로 보입니다.
Cursor와 Offset 개념이 이 현상에 대한 이해를 도울 수 있습니다. 커서(Cursor)와 오프셋(Offset)은 데이터베이스에서 페이지네이션을 구현하는 두 가지 주요 방식입니다.
- Cursor와 Offset
- Offset 기반 페이지네이션은 전체 데이터를 특정 페이지 단위로 나누어 오프셋부터 지정된 개수만큼 데이터를 조회하는 방법입니다
- SQL에서는 주로 LIMIT과 OFFSET 키워드를 사용합니다.
- 예:
SELECT * FROM 테이블_이름 LIMIT 오프셋_값, 페이지_사이즈 - 장점
- 구현이 간단하고 직관적입니다
- 단점
- 큰 오프셋 값에서 성능 저하가 발생할 수 있습니다
- 데이터 중복이나 누락이 발생할 수 있습니다
- Cursor 기반 페이지네이션은 이전에 반환된 마지막 데이터의 식별자를 기준으로 다음 데이터를 조회하는 방식입니다
- 예:
SELECT * FROM post WHERE id < 커서_값 LIMIT 페이지_사이즈 - 장점
- 성능이 일정하며, 데이터 양에 상관없이 효율적입니다
- 데이터 중복이나 누락 문제를 해결할 수 있습니다
- 단점
- 구현이 오프셋 방식보다 복잡할 수 있습니다
- 예:
필터 순서가 퍼포먼스에 끼치는 영향
필터 순서도 퍼포먼스에 많은 영향을 끼칩니다.
필터 순서가 퍼포먼스에 영향을 끼치는 이유는 가장 제한적인 필터를 먼저 적용하면 초기 데이터 세트를 크게 줄일 수 있기 때문입니다. 예시로 알아보겠습니다.
시나리오 설정
- 데이터 타입: 제품(Product)
- 관련 필드: 국가(Country), 가격(Price)
데이터 분포
- 국가별 분포
- 한국(Korea): 100,000개
- 중국(China): 1,000개
(즉, 국가만 따졌을 때 중국 제품이 훨씬 적음)
- 가격별 분포
- 10,000원 미만: 총 80,000개
- 한국: 79,500개
- 중국: 500개
- 10,000원 이상: 총 20,000개
(즉, 가격 기준으로 보면 저가 제품이 훨씬 적음) - 한국: 19,500개
- 중국: 500개
예시 상황: “중국 제품 중에서 10,000원 이상인 제품” 찾기
우리가 원하는 결과:
- 국가 = 중국
- 가격 >= 10,000원
- AND 조건
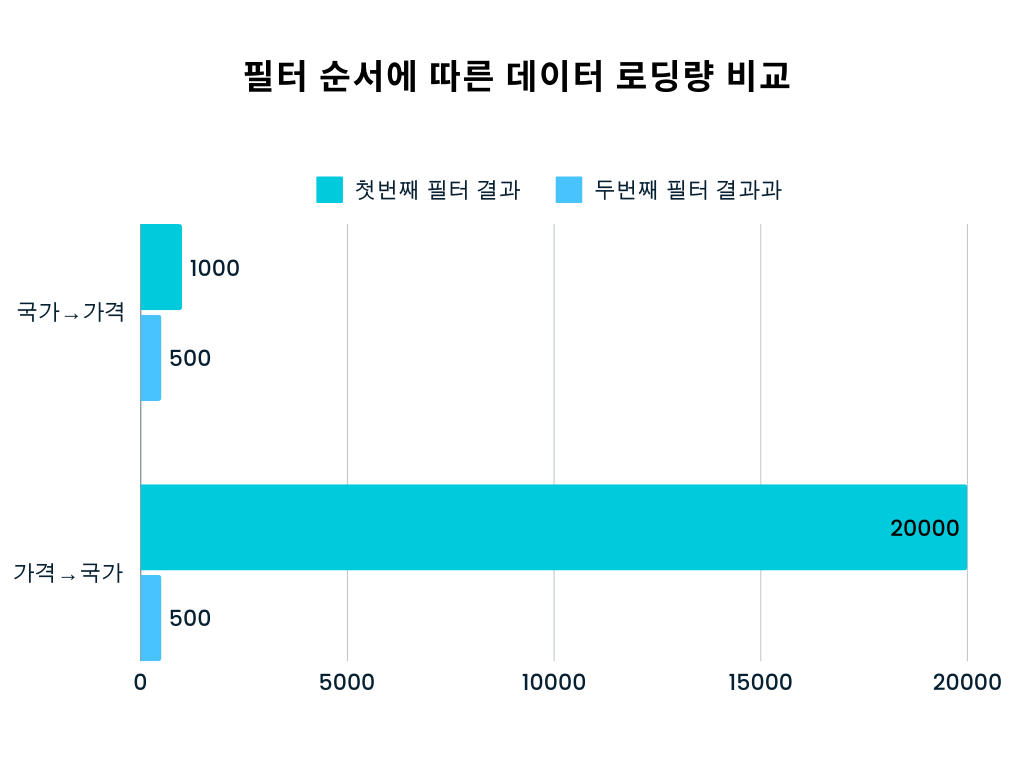
필터 순서에 따른 데이터 로딩량 비교
A. 국가(중국) 필터를 먼저 적용하는 경우
- 국가 = 중국 필터로 1차 검색:
- 총 1,000개의 데이터를 불러옴
- 이후 1,000개 중에서 가격 >= 10,000원인 제품만 거름:
- 500개만 해당됨
이번에는 첫 단계부터 불러온 데이터가 1,000개뿐이므로, 이중에서 500개만 제외하면 됩니다.
B. 가격(10,000원 이상) 필터를 먼저 적용하는 경우
- 가격 >= 10,000원 필터로 1차 검색:
- 총 20,000개의 데이터를 불러옴
- 이후 20,000개 중에서 국가 = 중국인 제품만 거름:
- 500개만 해당됨
결과적으로 필터 적용 과정에서 1차로 20,000개의 아이템을 전부 로드한 뒤, 그중에서 19,500개는 최종적으로 제외되는 셈입니다.
왜 이렇게 차이가 날까?
- 가장 제한적인 필터(데이터 개수가 적게 나오는 조건)를 먼저 적용하면,1차 필터에서 이미 데이터 풀을 대폭 줄일 수 있으므로,2차 필터에서는 훨씬 적은 양의 데이터를 확인하기만 하면 됩니다.
- 이 내용을 염두에 두고 검색과 필터를 구성하면, 데이터 개수가 많은 경우에도 비교적 빠른 응답을 유도할 수 있습니다.
2개 이상의 Data Type을 다루어야 할때 Advanced Filter 사용을 줄이는 방법
2개 이상의 Data Type이 연결되어있어서 DB에 직접 쿼리 실행하는것이 어려운 경우, 별도의 Data Field 만들어서 디비 생성/수정할때 업데이트해서 관리합니다.
- 이렇게 하면 검색할때 Advanced Filter를 사용하지 않아도 되어서 속도 측면에서 크게 개선됩니다.
- 다만 데이터를 생성/수정 할 때마다 최신화가 되도록 잘 관리해줘야한다는 단점이 있습니다. 이 부분에서 업데이트가 제대로 되지 않는다면 데이터가 누락되거나 잘못된 데이터를 보여주는 오류가 발생할 수 있습니다.
이러한 전략들을 꾸준히 적용하면, 데이터 규모가 커지더라도 버블 앱의 검색속도를 안정적으로 유지할 수 있습니다. 실제로 복합 검색이나 대규모 Data Type 간 연결이 필요한 상황에서도 불필요한 로드를 막는 설계를 도입하면, 사용자에게 보다 빠르고 쾌적한 경험을 제공할 수 있습니다.
버블의 특성상, 새로운 업데이트나 최적화가 계속 나오고 있으므로, 이 글에서 제시한 원칙을 기본으로 삼아 상황에 맞춰 유연하게 적용해보시기 바랍니다.
합리적인 외주 개발의 가치를 더하는 리트머스는 앞으로도 실무에서 얻은 노하우를 공유하며, 더 나은 개발 환경을 제공하기 위해 노력하겠습니다.







![[2025 최신] 버블에서 리피팅 그룹 각 셀마다 워크플로우를 실행하고 싶을 때 : 플러그인 오케스트라(Orchestra)](/_next/image?url=https%3A%2F%2Fuosmtaxndlzgvsnhbugi.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fmedia%2F12-1.jpg&w=3840&q=75)