

겉보기엔 멀쩡한데, 왜 이렇게 불안할까?
솔직히 말하면, 요즘 바이브 코딩은 정말 잘 되어 있습니다. Cursor, v0, GPT만 적절히 연결해도 웬만한 SaaS는 금방 형태를 갖춥니다. 로그인 화면이 뜨고, 대시보드가 보이고, 데이터 저장까지 돌아가기 때문에 겉으로 보기에는 “아, 이 정도면 서비스 되겠는데?”라는 생각이 들기 쉽습니다. 문제는 그 다음입니다. 그 상태에서 실제 유저를 받으려고 하면, 슬슬 설명하기 어려운 찝찝함이 올라오기 시작하죠.

바이브 코딩을 해보신 분들이라면 비슷한 고민을 한 번쯤은 해보셨을 겁니다.
- “이게 그냥 ‘대충 되는 것처럼 보이는 상태’인지, 아니면 진짜 서비스로 써도 될 만큼 제대로 된 건지 모르겠다.”
- “코드는 돌아가는데… 이걸 AI가 만든 게 맞는 걸까? 내가 못 본 구멍이 있는 건 아닐까?”
- “DB 구조나 보안, 스케일링 같은 건 솔직히 전문 분야라 뭐가 맞는지 판단하기 어렵다.”
여기에 더해, 구체적인 걱정도 따라옵니다.
- “카카오·구글 로그인을 붙이긴 했는데, 정말 안전한 설정이 맞나?”
- “봇이 가입이나 로그인을 계속 때리면 어떻게 막아야 하지?”
- “결제까지 붙여 놓긴 했는데, 실제로 돈이 오가는 상황에서 문제 생기면 어떻게 감당하지?”
- “내가 만든 이 서비스가 유저 100명만 동시에 들어와도 버틸까?”
- “로컬 테스트에서는 멀쩡하다는데, 실제 운영 환경은 완전 다른 세상이라던데…”
- “AI가 만들어준 설정과 기본값을 그냥 믿고 써도 되는 걸까, 아니면 내가 뭘 더 손봐야 하는 걸까?”
이런 걱정은 전혀 이상한 것이 아닙니다. 지금은 ‘코드를 작성하는 것’ 자체는 엄청 쉬워진 시대이지만, ‘운영·보안·스케일링까지 쉽게 끝나는 시대’는 아직 아닙니다. 코드를 짜는 허들은 낮아졌지만, 서비스로 버티게 만드는 허들은 그대로 남아 있는 셈입니다.
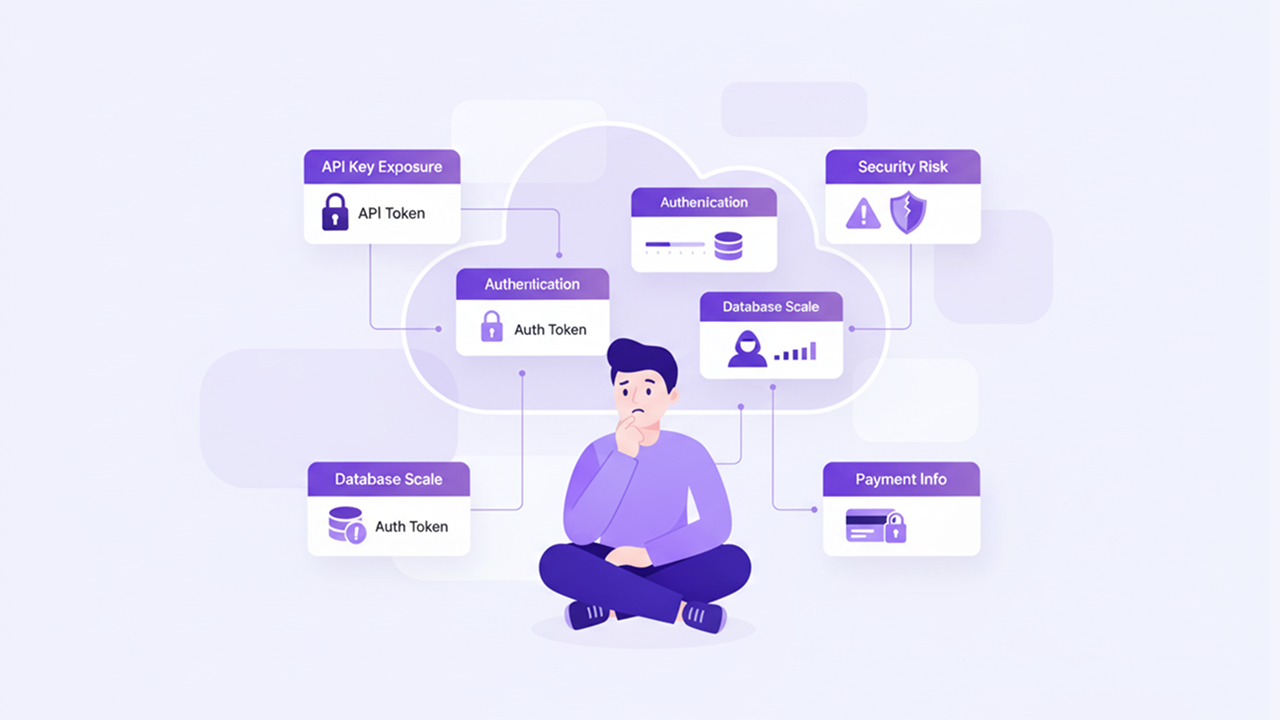
외주 개발사 입장에서 실제로 자주 보는 패턴들
리트머스처럼 다양한 SaaS 외주 개발·점검 프로젝트를 수행하는 팀 입장에서 보면, 위와 같은 고민은 요즘 정말 흔하게 마주치는 유형입니다. 최근 1~2년 사이에 가장 많이 들어오는 상담 유형을 한 줄로 요약하면 이런 형태입니다.
“AI로 1차 서비스는 만들어봤는데,
막상 실제 운영하려고 보니 너무 불안합니다.
어디가 위험한지, 무엇부터 손봐야 할지 모르겠어요.”
이런 프로젝트를 실제로 점검해 보면, 비슷한 문제들이 반복해서 발견됩니다.
- RLS(행 수준 보안)가 비활성화되어 있어, 사실상 테이블 전체가 모두에게 열려 있는 구조
- Rate Limit(요청 제한) 미적용으로, 봇이 가입·로그인·특정 API를 반복 호출하면 그대로 서비스가 흔들리는 상황
- 인증 토큰·세션 관리 미흡으로, 한 번 발급된 토큰이 사실상 반영구적으로 재사용 가능한 구조
- API Key가 프론트엔드 번들에 그대로 포함되어 있어, 빌드 파일만 뜯어보면 누구나 키를 확인할 수 있는 상태
- 데이터베이스 인덱스 미설정으로, 유저가 30~50명만 쌓여도 조회 성능이 급격히 떨어지는 테이블 구조
- 배포 파이프라인 부재로, 매번 수동 배포를 하다가 파일 하나씩 빠지거나 꼬이면서 점점 관리가 어려워지는 코드베이스
- 로그·모니터링 체계가 거의 없음에 따라, 문제가 발생해도 “그냥 안 됩니다” 이상의 원인 분석이 어려운 상황
- 이미지·파일 업로드에 대한 가드 없음으로, 악성 파일이 그대로 업로드될 수 있는 위험
- 클라우드/인프라 기본 정책을 그대로 사용해 불필요한 포트나 권한이 열려 있는 구성
- 캐싱이 전혀 없는 아키텍처로, 트래픽이 늘어나는 만큼 서버비와 부하가 그대로 상승하는 구조
이런 문제들은 “개발 실력이 부족해서”라기보다, 오히려 AI가 너무 빠르게 ‘겉모습이 갖춰진 서비스’를 만들어주기 때문에 더 잘 발생하는 유형입니다. 화면은 돌아가고, 기본 플로우도 동작하니 “이 정도면 되겠지”라는 안도감이 생기지만, 서비스는 문제가 없어 보일 때가 아니라 실제 문제가 터졌을 때 진짜 상태가 드러납니다. 그 순간에 비로소 “아, 처음부터 몇 가지는 더 챙겨뒀어야 했구나”라는 생각을 하게 되는 경우가 많습니다.

왜 ‘체크리스트’를 만들게 되었는가
외주 개발사 입장에서 여러 SaaS를 직접 만들고, 운영하고, 장애를 수습해 보는 과정을 반복하다 보면 하나의 공통된 결론에 도달하게 됩니다.
“적어도 이 정도 리스트는 기본값처럼 챙겨야 한다.”
처음에는 “지금 당장 필요한 최소한의 보안/운영 체크리스트 정도만 정리해보자”는 생각으로 시작했습니다. 하지만 실제 현장에서 반복적으로 문제가 되는 지점들을 모으다 보니, 자연스럽게 필수에 가깝게 챙겨야 하는 요소들까지 포함된 리스트가 만들어졌습니다.
이렇게 리스트를 확장하게 된 이유는 명확합니다. 실제 프로젝트를 여러 번 수행해 보면, 사전에 약간만 준비해 두어도 전체 사고의 80% 정도는 미리 막을 수 있다는 사실을 체감하게 되기 때문입니다. 특히 다음과 같은 부분에서 그런 경험이 많이 쌓입니다.
- 유저가 몰릴 때마다 반복해서 깨지는 지점들
- AI 코드 어시스턴트가 통째로 빼먹는 보안·운영 관련 설정
- 실제 고객사들이 가장 자주 실수하는 패턴
- 여러 번 장애를 겪고 나서야 깨닫게 되는 “운영 단계에서의 디테일”
이 글에서 다루는 체크리스트는 바로 이런 경험을 바탕으로 구성되었습니다. 바이브 코딩으로 만든 서비스라도, 이 정도 항목을 기준 삼아 한 번씩 점검해 두면 훨씬 안정적인 론칭이 가능해집니다. 이 글을 읽는 분들이 “최소한 이 정도는 챙겼으니, 서비스가 기본적인 상황에서는 버티겠다”라는 수준의 안심을 가져가실 수 있다면 이 글의 목적은 충분히 달성된 것이라고 생각합니다.
이제부터는 실제로 어떤 항목들을 점검해야 하는지, 개발을 막 시작한 분도 따라올 수 있도록 차근차근 살펴보겠습니다.
1. 엔드포인트에 Rate Limit(요청 제한) 적용하기
먼저 가장 기본적인 개념부터 정리해 보겠습니다. “엔드포인트”는 백엔드에서 제공하는 API 주소 한 개를 의미합니다. 예를 들어 /api/login, /api/signup, /api/checkout 같은 각각의 URL이 모두 하나의 엔드포인트입니다. “Rate Limit”은 특정 사용자(또는 특정 IP)가 이 주소로 얼마나 자주 요청을 보낼 수 있는지를 제한하는 규칙입니다.
이 규칙이 전혀 없는 상태에서는, 누군가 악의적으로 혹은 단순한 실수로 특정 API를 초당 수백, 수천 번씩 호출해도 막을 수단이 없습니다. 그 결과 데이터베이스 커넥션이 모두 소진되어 전체 서비스가 중단되거나, Supabase·서버리스 호출량이 폭발적으로 증가해 비용 문제가 발생할 수 있습니다. 비밀번호를 무차별 대입하는 Brute force 공격 역시 이런 취약점을 노립니다.
Supabase와 Edge Function을 활용한 Rate Limit 예시
Supabase를 사용하는 경우에는 보통 Edge Function에 간단한 저장소(KV, Redis 등)를 조합하는 방식이 많이 쓰입니다. 흐름은 다음과 같이 이해하면 됩니다.
- Supabase 대시보드에서 프로젝트 선택 후, 왼쪽 메뉴의 Functions(Edge Functions)로 이동합니다.
- 예를 들어
login-handler처럼 의미가 분명한 이름으로 새 Edge Function을 생성합니다. 앞으로 로그인이나 비밀번호 재설정처럼 민감한 요청은 이 함수를 거치도록 설계합니다. - 함수 내부에서는 요청이 들어올 때마다 “해당 IP(또는 user_id)가 최근 1분 동안 이 엔드포인트를 몇 번 호출했는지”를 저장소에 기록합니다.
- 이 호출 횟수가 미리 정한 기준(예: 분당 5회, 10회 등)을 넘으면 HTTP 429(Too Many Requests)를 반환하고, 실제 비즈니스 로직은 실행하지 않습니다.
- 프론트엔드에서는 기존에 직접 호출하던
/api/login대신,https://<project>.functions.supabase.co/login-handler같은 Edge Function URL을 호출하도록 수정합니다.
로그인·비밀번호 재설정, 결제 요청처럼 민감하거나 비용이 많이 드는 엔드포인트부터 우선적으로 Rate Limit을 적용하는 것이 좋습니다. 기준 자체는 “일반 사용자가 쓰기에 불편하지 않은 수준” 안에서 잡되, 봇이나 공격자가 무차별 호출을 하는 상황은 확실하게 차단할 수 있도록 여유 있게 설정하는 편이 안전합니다.
2. Supabase Row-Level Security(RLS) 활성화하기
Row-Level Security(RLS)는 이름만 보면 어렵게 느껴질 수 있지만, 개념은 비교적 단순합니다. 하나의 테이블에 여러 사용자의 데이터가 섞여 있을 때, 각 사용자가 자기 데이터에 해당하는 행(row)만 조회·수정할 수 있도록 제한하는 장치라고 이해하면 됩니다.
예를 들어 todos 테이블에 여러 사용자의 할 일이 함께 저장되어 있다고 가정해 보겠습니다. RLS가 꺼져 있으면, 이론적으로는 한 사용자가 다른 사용자의 할 일까지 조회할 수 있는 구조가 됩니다. 반대로 RLS를 활성화하고 “auth.uid() = user_id인 행만 조회할 수 있다”는 정책을 만들면, 각 사용자는 자신의 데이터만 볼 수 있게 됩니다.
Supabase에서 RLS를 켜는 단계
Supabase에서는 테이블 단위로 RLS를 켜고, 그 위에 정책(Policy)을 정의하는 방식으로 보안을 구성합니다.
- Supabase 대시보드에서 Table Editor로 이동합니다.
- 보호가 필요한 테이블(예:
profiles,orders,todos)을 선택합니다. - 상단 탭에서 RLS 또는 Security 관련 메뉴를 찾은 뒤, “Enable Row Level Security” 버튼을 눌러 RLS를 활성화합니다.
- 바로 아래에서 **Policies(정책)**를 추가합니다. Supabase Auth를 사용 중이라면 보통 다음과 같은 정책이 기본이 됩니다.
- 인증된 사용자(authenticated)는
user_id = auth.uid()인 행만 조회(SELECT) 가능 - 인증된 사용자는
user_id = auth.uid()인 행만 생성/수정(INSERT/UPDATE) 가능
- 인증된 사용자(authenticated)는
SQL로 표현하면 다음과 같은 형태를 떠올리시면 됩니다.
alter table public.todos enable row level security;
create policy "Users can view their own todos"
on public.todos
for select
to authenticated
using (auth.uid() = user_id);
create policy "Users can insert their own todos"
on public.todos
for insert
to authenticated
with check (auth.uid() = user_id);
관리자 권한은 별도의 흐름으로 관리하는 것이 일반적입니다. 예를 들어, 관리자 화면에서 사용하는 쿼리는 Next.js API Route나 Supabase Edge Function 안에서 서비스 키(service_role)로만 실행하고, 이 부분은 브라우저에서 직접 호출할 수 없게 만드는 식입니다.
이미지·파일 업로드를 위해 Supabase Storage를 쓰는 경우에도 유사한 개념이 적용됩니다. 버킷과 경로별로 접근 권한을 세밀하게 조정해 “누가 어디까지 업로드/다운로드할 수 있는지”를 정책으로 정의해두면 훨씬 안전한 구조를 만들 수 있습니다.
결론만 정리하면 다음과 같습니다.
- 유저 데이터가 들어가는 테이블에는 RLS를 기본값처럼 켜 두는 것이 안전하다.
- 처음에는
auth.uid() = user_id를 기준으로 잡고, 이후 필요에 따라 관리자·시스템 계정을 별도로 설계하는 방식으로 확장하는 편이 좋다.
3. 회원가입·로그인·비밀번호 찾기에 CAPTCHA 적용하기
AI 봇이 발전하면서, 이제는 사람처럼 폼을 채우고 계정을 만들어내는 일도 어렵지 않게 수행합니다. 이 상황에서 아무런 보호 장치 없이 회원가입·로그인 폼을 열어두면, 짧은 시간 안에 수백 개의 가짜 계정이 생성되거나 특정 계정을 대상으로 한 공격이 시도될 수 있습니다. 이 과정에서 이메일 발송 비용, DB 저장 비용, 외부 서비스 연동 비용 등은 그대로 발생하고, 통계 데이터 역시 왜곡됩니다.
이런 문제를 막기 위해 가장 널리 쓰이는 도구가 바로 CAPTCHA입니다. 대표적으로는 Google의 reCAPTCHA와 hCaptcha가 있습니다.
CAPTCHA를 적용해야 하는 주요 지점
CAPTCHA는 다음과 같은 지점에 우선적으로 적용하는 것을 권장합니다.
- 신규 회원가입(Signup) 폼
- 로그인(Login) 폼 (특히 동일 IP·동일 계정에서 반복적으로 실패하는 경우)
- 비밀번호 찾기·재설정(Reset Password) 폼
reCAPTCHA를 적용하는 기본 흐름
reCAPTCHA 기준으로 구축 흐름을 단순화하면 다음과 같습니다.
- Google reCAPTCHA 공식 페이지에 접속하여 Admin 콘솔에서 새 사이트를 등록합니다.
- 도메인(예:
myapp.com,localhost)과 사용할 유형(v2 체크박스, v3 등)을 선택한 뒤 저장하면,site key와secret key두 가지 키를 발급받습니다. - 프론트엔드(Next.js/React 기준)에서는
site key를 사용해 폼에 reCAPTCHA 위젯을 추가합니다. - 사용자가 폼을 제출하면, reCAPTCHA가 토큰을 함께 전달합니다.
- 이 토큰을 백엔드(Next.js API Route, Supabase Edge Function 등)로 전송합니다.
- 백엔드는
secret key와 토큰을 사용해 reCAPTCHA 검증 API를 호출하고, 결과가 정상일 때만 실제 회원가입·로그인 로직을 실행합니다.
hCaptcha 또한 비슷한 방식으로 동작하며, React/Next.js용 패키지를 활용하면 비교적 쉽게 통합할 수 있습니다. 이때 중요한 점은 두 가지입니다.
- 토큰 검증은 반드시 백엔드에서 수행해야 한다는 것
- CAPTCHA 실패나 비정상 시도는 로그에 남겨 나중에 패턴을 분석할 수 있게 해두는 것이 좋다는 것
4. Vercel Web Application Firewall(WAF) 활성화하기
Web Application Firewall(WAF)는 말 그대로 웹 애플리케이션을 대상으로 한 공격을 필터링하는 방화벽입니다. SQL Injection, XSS, 취약점 스캐닝, 비정상적인 봇 트래픽 등 흔히 발생하는 패턴을 자동으로 감지·차단하는 기능을 제공합니다.
Next.js와 Vercel을 사용하는 경우, 이 부분은 비교적 간단하게 시작할 수 있습니다. Vercel에는 Vercel Firewall / WAF / Bot Management 기능이 기본 제공되며, 대시보드에서 몇 가지 설정만 켜도 기본적인 보호 수준을 확보할 수 있습니다.
Vercel 사용 시 일반적인 흐름은 다음과 같습니다.
- Vercel 대시보드에 접속해 프로젝트를 선택합니다.
- 상단 혹은 좌측 메뉴에서 Firewall 탭을 찾습니다.
- 기본 WAF 기능과 Bot Management, Attack Challenge Mode 등을 활성화합니다.
/api/*,/auth/*,/checkout/*등 민감한 경로에 대해서는 좀 더 엄격한 규칙을 적용할 수 있습니다.
Attack Challenge Mode는 공격이 의심되는 요청에 대해 추가 검증을 요구해, 단순한 스크립트나 봇이 통과하기 어렵게 만드는 보호층입니다.
실제로 도메인이 공개되어 있다면, 이미 각종 스캐너·봇이 하루에도 수십 번씩 사이트를 찍고 지나갔을 가능성이 높습니다. WAF는 애플리케이션 코드에 손대지 않고도 이런 무의미하거나 위험한 트래픽을 한 번 걸러주는 필터이기 때문에, 기본값처럼 켜 두는 편이 훨씬 안전합니다.
5. API Key와 Secret은 절대 프론트엔드에 두지 않기
이 부분은 조금 과장해서 표현하면 다음과 같이 기억해 두면 편합니다.
“브라우저에서 실행되는 코드는 전부 공개된 것이다.”
프론트엔드 번들은 누구나 내려받을 수 있고, 마음만 먹으면 코드와 문자열을 분석할 수 있습니다. 따라서 프론트 코드 안에 API Key나 Secret이 포함되어 있으면, 사실상 유출된 것과 다름없습니다.
대표적으로 피해야 할 패턴은 다음과 같습니다.
- OpenAI, 결제 PG, 외부 API에 대한 Secret Key를 React 컴포넌트 코드 안에서 직접 사용하는 경우
NEXT_PUBLIC_...형태의 환경 변수에 시크릿 값을 넣는 경우- 브라우저에서 호출되는 JavaScript 코드 안에서 Authorization 헤더에 Secret을 직접 삽입하는 경우
대신 다음과 같은 원칙을 지키는 것이 좋습니다.
- 모든 Secret은 서버 환경변수와 백엔드 코드에서만 사용합니다.
- 프론트엔드는 항상 서버(또는 Edge Function)를 경유해 민감한 외부 API를 호출합니다.
- AI가 생성한 예제 코드라도, Secret을 어디에서 어떻게 사용하는지 반드시 한 번 직접 확인합니다.
간단히 정리하면, “비밀번호를 입력해야 하는 로직은 모두 서버에 있어야 한다”라고 생각하시면 됩니다. 프론트는 토큰이나 입력값을 받아 서버로 전달하는 역할에 집중시키고, 실제 민감한 정보와 통신하는 부분은 백엔드 전용 코드로 격리하는 것이 안전한 구조입니다.
6. 모든 입력은 프론트가 아닌 백엔드에서 검증하기
Cursor, Lovable, v0 같은 도구가 생성하는 폼에는 이미 꽤 많은 UI 레벨의 검증 로직이 포함되어 있습니다. 이메일 형식 검사, 비밀번호 길이 제한, 필수 입력값 체크 등이 대표적입니다. 다만 이 부분에 대해 꼭 짚고 넘어가야 할 원칙이 있습니다.
“프론트엔드 검증은 사용자 편의를 위한 안내일 뿐, 보안 장치가 아니다.”
사용자는 브라우저 개발자 도구를 열어 폼 검증을 우회할 수 있고, Postman 같은 도구를 사용해 API를 직접 호출할 수도 있습니다. 따라서 중요한 검증은 언제나 백엔드에서 한 번 더 수행해야 합니다.
백엔드에서 확인해야 하는 항목의 예시는 다음과 같습니다.
- 이메일, 비밀번호 형식 및 길이
- 문자열 필드의 최소·최대 길이
- enum 타입 필드의 값이 허용된 집합 안에 있는지 여부
- 파일 업로드의 경우 확장자, MIME 타입, 용량 제한
- 외부 API에 전달하는 데이터의 스키마 검증 여부
이를 구현하는 방법으로는 zod, yup, valibot 등 스키마 기반 검증 라이브러리를 프론트·백엔드에서 공통으로 사용하는 방식이 많이 쓰입니다. 예를 들어, Next.js API Route 시작 부분에서 입력값을 스키마로 검증한 뒤, 검증에 통과한 데이터에 대해서만 실제 비즈니스 로직을 수행하도록 구조를 잡는 것입니다.
파일 업로드의 경우에는 특히 주의가 필요합니다.
- 허용 확장자 목록을 명확히 정의하고
- MIME 타입을 함께 검증하며
- 용량 상한을 지정하고
- 가능하면 실제 파일 내용을 추가로 점검하는 절차까지 준비해 두는 것이 좋습니다.
이렇게 다단계로 필터링을 구성해 두면, 악성 파일이 업로드 경로를 통해 유입되는 위험을 상당 부분 줄일 수 있습니다.
7. 의존성(Dependencies) 정리와 취약점 점검하기
AI 도구와 함께 개발하다 보면, 의존성이 빠르게 늘어나는 패턴을 자주 경험하게 됩니다.
- 특정 기능을 구현하기 위해 AI가
npm install명령어를 여러 개 추가하고 - 다른 기능을 붙이면서 또 새로운 패키지가 설치되고
- 시간이 지나면
package.json에는 실제로는 사용하지 않는 라이브러리까지 함께 쌓이게 됩니다.
사용하지 않는 패키지가 많아질수록 공격 표면이 넓어지고, 빌드 시간과 번들 크기가 불필요하게 커집니다. 또한, 오래된 취약 버전 패키지가 그대로 남아 있을 가능성도 높아집니다. 따라서 서비스 론칭 전에는 한 번쯤 의존성 다이어트와 보안 점검을 해주는 것이 안전합니다.
가장 기본적으로 활용할 수 있는 도구는 npm audit 또는 yarn audit입니다.
npm audit --production,npm audit fix --productionyarn audit --groups dependencies
이 명령어를 통해 현재 사용 중인 패키지에 알려진 취약점이 있는지 확인할 수 있고, critical, high 등급 이슈가 표기된 패키지는 버전 업데이트나 대체 패키지 적용을 검토하는 것이 좋습니다.
또한 IDE에서 “사용되지 않는 import”라고 표시되는 라이브러리는 코드에서 제거한 뒤, npm uninstall 또는 yarn remove로 실제 패키지도 함께 정리해 주는 편이 좋습니다.
이상적인 상태는,
- 프론트엔드에는 꼭 필요한 UI·상태 관리 라이브러리만 남겨두고
- 백엔드에는 DB 접속 및 필수 기능 구현에 필요한 최소한의 라이브러리만 유지하며
- 이 외의 보조적 라이브러리는 실제로 사용하는지 주기적으로 점검하는 것
이라고 보시면 됩니다. AI가 “일단 돌아가게 하려고” 가져온 의존성들은, 실제로 프로젝트에 꼭 필요한가를 다시 한 번 검토해 보는 것이 좋습니다.
8. 최소한의 모니터링과 로그 체계 구축하기
서비스 운영에서 자주 마주치는 난감한 상황 중 하나는, 장애가 발생했다는 이야기를 듣고도 무엇이, 언제, 어떻게 잘못되었는지 확인할 근거가 없는 상태입니다. 예를 들어 다음과 같은 경우입니다.
- “어제 밤에 로그인 오류가 많았던 것 같은데, 정확히 몇 건이었는지 모른다.”
- “특정 시간대에만 응답이 느려졌다고 하는데, 서버에서는 특별한 기록이 남아 있지 않다.”
이런 상황을 줄이려면, 적어도 다음 세 가지 유형의 정보는 로그와 모니터링으로 확인할 수 있어야 합니다.
- 인증 관련 이벤트
- 로그인 성공·실패 기록
- 비밀번호 재설정 요청
- 특정 IP에서 반복되는 로그인 실패
- 트래픽·성능 지표
- 엔드포인트별 요청 수
- 응답 시간 분포, 특정 시간대의 급격한 변화
- 에러 정보
- 500(서버 에러) 발생 횟수
- 동일한 에러 메시지가 짧은 시간 안에 반복되는지 여부
Supabase를 사용 중이라면 Logs Explorer를 통해 DB·Storage·Auth·Edge Functions 로그를 한 화면에서 볼 수 있고, 필요하면 외부 모니터링 시스템으로 로그를 내보내는 Log Drains 기능을 활용할 수도 있습니다. Vercel의 경우에도 기본적인 Analytics, Speed Insights, Function 로그 등을 통해 트래픽과 오류 상황을 파악할 수 있습니다.
외부 도구까지 도입하기 부담된다면, 가장 단순한 접근으로 Supabase에 app_logs 같은 테이블을 하나 만들고 중요한 이벤트를 직접 기록하는 방법이 있습니다. 예를 들어 다음과 같이 테이블을 구성하고,
create table public.app_logs (
id bigserial primary key,
created_at timestamptz default now(),
level text, -- 'info' | 'warn' | 'error'
event text, -- 예: 'login_failed'
user_id uuid,
ip inet,
payload jsonb
);
Edge Function이나 서버 코드에서 로그인 실패, Rate Limit 초과, 예외 발생 등의 상황마다 한 줄씩 로그를 쌓아두면, 나중에 특정 시간대에 무슨 일이 있었는지 되짚어 보는 데 큰 도움이 됩니다.
보너스: 이 글에서 깊게 다루지는 않았지만 반드시 고려해야 할 요소들
앞에서 간단히 언급만 했지만, 실제 서비스를 운영하다 보면 다음과 같은 요소들도 반복적으로 문제가 되곤 합니다.
- 데이터베이스 인덱스 설계
초기에는 데이터가 적어 문제를 느끼지 못하지만, 유저 수가 늘어나면서 특정 조회 쿼리의 성능이 급격히 떨어지는 경우가 많습니다. 자주 조회하는 컬럼(user_id, created_at, status 등)에 적절한 인덱스를 설정해 두는 것이 중요합니다.
- 배포 파이프라인(CI/CD) 구축
사람이 직접 파일을 수정하고 서버에 업로드하는 방식은 단기적으로는 빨라 보일 수 있지만, 장기적으로는 실수와 누락을 불러오기 쉽습니다. Git 커밋 → 테스트 → 빌드 → Vercel/Supabase 배포까지 자동화된 흐름을 한 번 만들어 두면, 배포와 관련된 리스크를 크게 줄일 수 있습니다.
- 이미지·파일 업로드 보호
업로드 가능한 파일 타입, 저장 위치, 접근 권한을 명확히 관리하지 않으면 악성 파일이 유입될 위험이 있습니다. Supabase Storage와 RLS를 적절히 조합해 사용자별·역할별 접근 범위를 제한해 두는 것이 좋습니다.
- 캐싱 전략 수립
공지사항, 상품 목록, 블로그 게시글처럼 자주 바뀌지 않는 데이터는 Edge Cache나 Next.js의 ISR(Incremental Static Regeneration) 등을 활용해 캐싱하면, 트래픽이 늘어나도 서버 부하와 비용을 안정적으로 관리할 수 있습니다.
각 항목만으로도 한 편의 글이 될 수 있는 주제들이지만, 공통점은 하나입니다. 시간이 지날수록 언젠가는 반드시 손대야 하는 영역이라는 점입니다. 초기 단계에서 전부 완벽하게 구현할 필요는 없지만, “지금은 어디까지 되어 있고, 다음 단계에서 무엇을 강화해야 하는지” 정도는 머릿속에 그려 두는 것이 좋습니다.
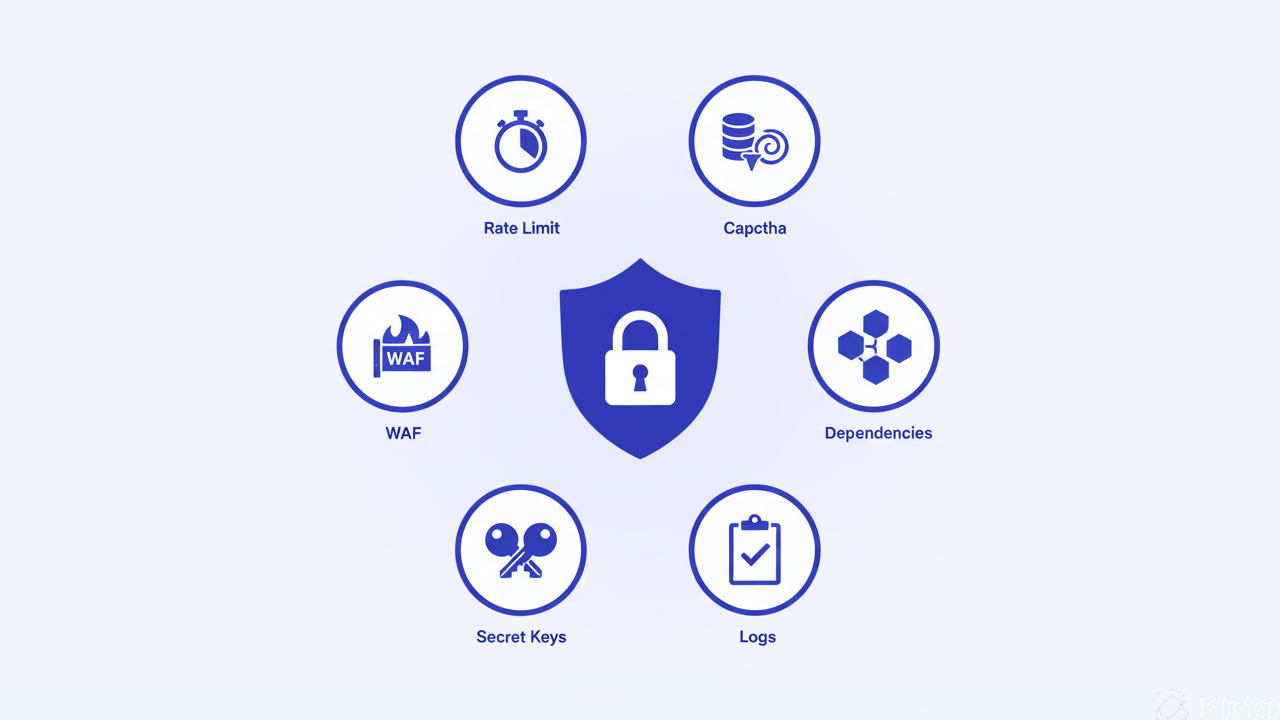
마무리: 완벽한 보안보다, “이 8가지는 기본값”이라는 기준 세우기
바이브 코딩 시대에는 코드를 작성하는 속도만 놓고 보면 AI와 함께 개발하는 팀이 압도적으로 유리합니다. 하지만 실제 운영까지 포함해 서비스를 바라보면, 결국 중요한 기준은 조금 다릅니다.
“이 8가지 기본 체크는 이미 끝냈는가?”
다시 정리하면 다음과 같습니다.
- 민감한 엔드포인트에 Rate Limit(요청 제한) 적용하기
- Supabase에서 유저 데이터 테이블에 Row-Level Security(RLS) 활성화하기
- 회원가입·로그인·비밀번호 찾기 플로우에 CAPTCHA 도입하기
- Vercel 등에서 제공하는 Web Application Firewall(WAF) 기본 보호 켜기
- API Key·Secret을 절대 프론트엔드에 두지 않고, 서버 전용 코드에서만 사용하기
- 모든 입력값을 백엔드 스키마 검증을 통해 한 번 더 확인하기
- 의존성 정리와 취약점 점검(npm/yarn audit)을 통해 공격 표면 줄이기
- 최소한의 로그·모니터링 체계를 구축해 장애 원인을 추적할 수 있게 만들기
이 정도만 체계적으로 점검해도,
- “AI가 대충 만든 것 같아 불안하다”는 감정,
- “유저 100명만 와도 서비스가 버틸지 모르겠다”는 고민
을 상당 부분 줄일 수 있습니다.
리트머스와 함께 바이브 코딩을 ‘운영 가능한 서비스’로 만들고 싶다면
리트머스는 단순히 화면을 빠르게 만드는 팀이 아니라, AI·바이브코딩을 활용해 실제 운영까지 견디는 SaaS를 설계·구현하는 외주 개발사입니다. Cursor, v0, GPT 같은 도구를 적극적으로 활용해 개발 속도를 높이되, 위에서 정리한 보안·운영·스케일링 체크리스트를 기반으로 서비스가 버티는 구조를 함께 설계하는 데 강점을 가지고 있습니다.
다른 외주사와 비교했을 때 리트머스가 특히 집중하는 부분은 다음과 같습니다.
- 초기 설계 단계부터 데이터 구조·보안·스케일링을 함께 보는 기획 역량
- AI 도구를 활용해 빠르게 구현하면서도, RLS·Rate Limit·WAF·로깅 등 기본 안전장치를 놓치지 않는 개발 프로세스
- 6주 MVP와 같이, 제한된 기간 안에 실제 유저를 받을 수 있는 수준의 완성도를 목표로 하는 단계별 접근법
이미 AI로 1차 프로토타입을 만들어 놓았지만 “이 상태로 운영에 올려도 되는지” 고민되신다면, 혹은 처음부터 바이브 코딩을 전제로 한 외주 개발 파트너가 필요하시다면 한 번 상담을 받아보셔도 좋습니다.
우리 프로젝트가 바이브코딩 외주에 적합한지, 그리고 6주 MVP 방식이 필요한지 함께 진단해 드립니다.
지금 바로 리트머스에 문의해 보세요! 무료 견적 상담을 남겨주시면, 현재 서비스 상태와 다음 단계에서 어떤 보완이 필요한지까지 함께 안내해 드리겠습니다.







![[2026년 4월 최신] 오픈클로 완벽 가이드: 뜻, PC 설치 방법부터 실무 활용 사례까지](/_next/image?url=https%3A%2F%2Fuosmtaxndlzgvsnhbugi.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fmedia%2Ffile-18.png&w=3840&q=75)