

이 글은 Cursor 공식 블로그 가이드 「Best practices for coding with agents」(2026.01.09)를 바탕으로, 핵심 흐름과 실무 팁을 한국어로 정리한 내용입니다.
「Best practices for coding with agents」 바로가기
에이전트와 함께 코딩할 때의 베스트 프랙티스
AI 코딩 에이전트는 소프트웨어가 만들어지는 과정을 바꿔놓고 있습니다. 모델이 몇 시간씩 실행되며 여러 파일을 가로지르는 리팩터링을 해내고, 테스트가 통과할 때까지 스스로 반복하는 시대가 열렸습니다. 다만 에이전트의 성능을 그대로 생산성으로 바꾸려면, 에이전트가 어떤 원리로 움직이는지 이해하고 그에 맞는 작업 패턴을 갖추는 편이 빠릅니다.
이 글은 Cursor의 에이전트를 기준으로, 처음 AI 에이전트 코딩을 접하는 분부터 팀 차원에서 운영 방식을 정리하고 싶은 분까지를 대상으로 합니다. Cursor 팀이 실제로 현업에서 적용해 온 원칙을 바탕으로, “잘 되는 방식”을 재현 가능한 형태로 정리했습니다. 중간중간 도구 설정과 예시 코드를 함께 제시하니, 본인 레포에 그대로 가져다 적용해도 무리가 없을 겁니다.
에이전트 하네스 이해하기
에이전트 하네스(agent harness)는 세 가지 구성 요소를 묶어 한 번의 작업 흐름으로 만드는 구조입니다. 첫 번째는 에이전트의 행동을 규정하는 시스템 프롬프트와 규칙 같은 Instructions이고, 두 번째는 파일 편집, 코드베이스 검색, 터미널 실행 등 실제 작업을 수행하는 Tools입니다. 세 번째는 사용자가 던지는 프롬프트와 후속 메시지로, 작업 방향과 우선순위를 잡아주는 User messages입니다.
Cursor의 에이전트 하네스는 이 세 요소를 모델별로 조합해 오케스트레이션합니다. Cursor는 내부 평가(evals)와 외부 벤치마크를 바탕으로, 지원하는 각 모델에 맞게 Instructions와 Tools를 세밀하게 튜닝합니다. 같은 프롬프트를 줘도 모델마다 선호하는 작업 방식이 달라서, 하네스의 설계가 결과를 크게 좌우합니다.
예를 들어 셸 중심 워크플로우에 익숙한 모델은 전용 검색 도구보다 grep을 더 자연스럽게 쓸 수 있고, 다른 모델은 편집 뒤에 린터 호출을 명시적으로 요구해야 안정적으로 움직일 수 있습니다. 하네스가 이런 차이를 흡수해 주면, 사용자는 새 모델이 나와도 “도구 적응”보다 “제품 만들기”에 집중할 수 있습니다.
계획부터 시작하기
AI 에이전트 코딩에서 가장 큰 변화를 만드는 습관은, 코드를 쓰기 전에 계획을 세우는 일입니다. 작업을 바로 던지기보다 먼저 목표와 범위를 고정하면, 에이전트가 헤매는 시간이 눈에 띄게 줄어듭니다. 계획은 “무엇을 만들지”를 명확히 할 뿐 아니라, “언제 완료인지”를 정의해 에이전트가 스스로 검증하며 나아가게 해줍니다.
University of Chicago의 연구에서는, 숙련된 개발자일수록 코드를 생성하기 전에 계획을 세우는 경향이 더 높다고 보고했습니다. 이 차이는 단순한 습관 문제가 아니라, 복잡한 작업을 다룰 때의 사고 방식과 연결됩니다. 에이전트에게 일을 맡길수록 계획의 가치는 더 커지며, 이는 결국 결과물의 품질로 돌아옵니다.
Plan Mode 사용하기
Cursor 에이전트 입력창에서 Shift + Tab을 누르면 Plan Mode를 켤 수 있습니다. Plan Mode에서는 에이전트가 곧바로 코드를 작성하기보다, 먼저 요구사항을 확인하고 설계안을 만드는 데 집중합니다. 처음부터 “구현”이 아니라 “작업 설계”를 문서로 고정한다는 점이 핵심입니다.
Plan Mode에서 에이전트가 보통 수행하는 일은 아래와 같습니다.
- 코드베이스를 조사해 관련 파일을 찾아냅니다.
- 요구사항이 애매한 지점을 확인 질문으로 정리합니다.
- 파일 경로와 코드 레퍼런스를 포함한 구현 계획을 만듭니다.
- 사용자의 승인 후에만 실제 구현 단계로 넘어갑니다.
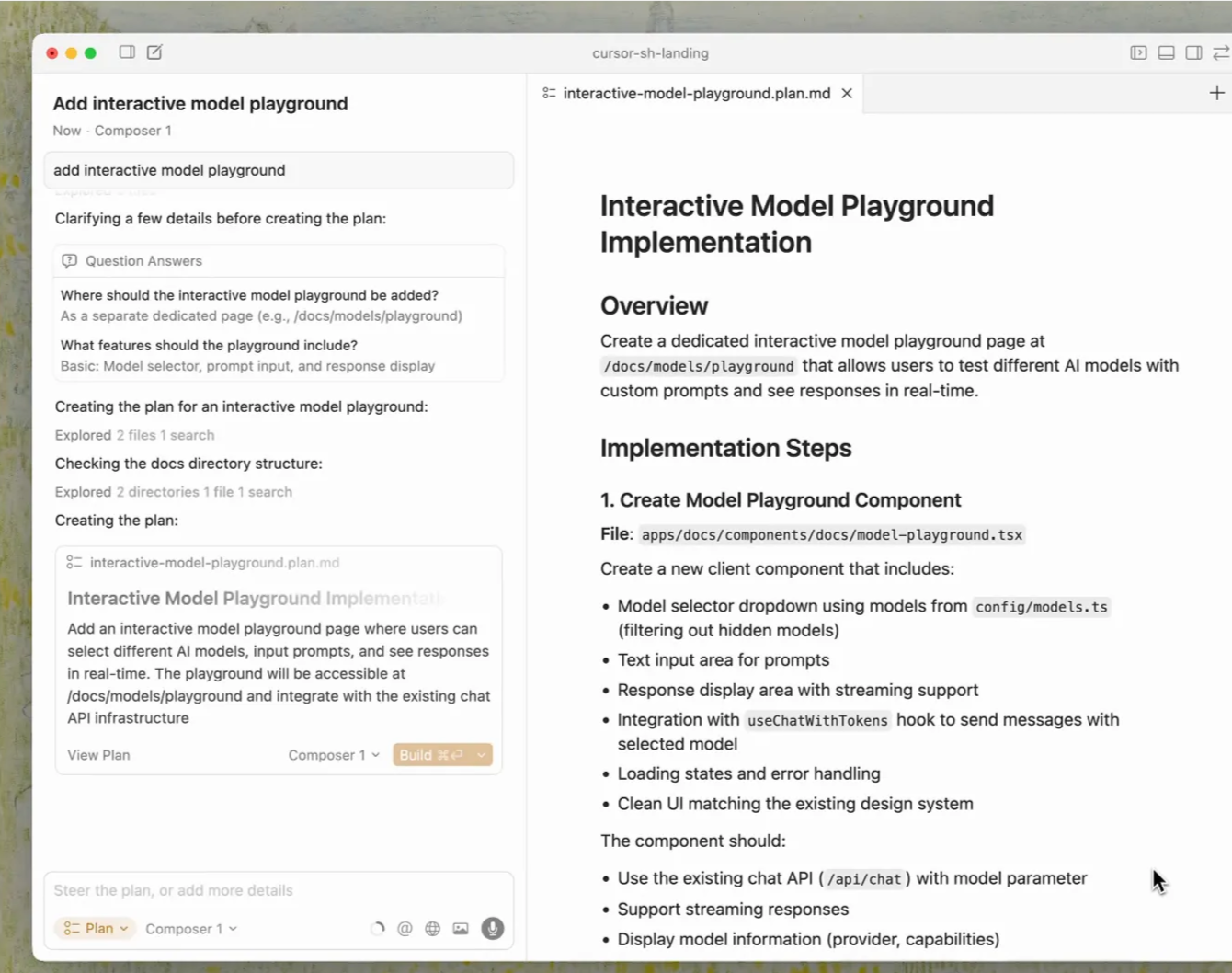
Plan Mode 시연: 에이전트가 확인 질문을 던지고, 검토 가능한 계획을 작성하는 모습 (출처 : Cursor, 2026)
계획은 Markdown 파일로 열리며, 사용자가 직접 수정할 수 있습니다. 불필요한 단계는 덜어내고, 접근 방식을 바꾸고, 빠진 전제를 보강하는 식으로 “의도”를 더 정확히 기록해두면 이후 구현이 훨씬 매끄러워집니다. 특히 “Save to workspace”로 계획을 .cursor/plans/에 저장하면, 중단된 작업을 재개하거나 팀에서 맥락을 공유하는 데 큰 도움이 됩니다.
물론 모든 작업이 긴 계획을 필요로 하진 않습니다. 반복적으로 해오던 간단한 수정이라면 바로 구현으로 들어가도 충분할 때가 많습니다. 다만 여러 파일이 얽히거나, 리팩터링 범위가 커질 가능성이 보이면 Plan Mode로 시작하는 편이 대개 이득입니다.
계획에서 다시 시작하기
에이전트가 만든 결과가 원하는 방향과 다를 때가 있습니다. 이럴 때는 후속 프롬프트로 억지로 교정하기보다, 계획으로 돌아가 다시 시작하는 편이 빠른 경우가 많습니다. 변경 사항을 되돌리고, 계획을 더 구체적으로 다듬은 뒤 재실행하세요.
진행 중인 산출물을 “수정으로 살리려는 노력”보다, 계획을 정교화해 “처음부터 다시 빌드”하는 방식이 결과를 더 깔끔하게 만듭니다. 특히 대규모 리팩터링처럼 구조가 흔들리기 쉬운 작업에서는, 중간에 방향을 틀어 수선하는 것보다 처음부터 명확한 설계로 밀고 가는 편이 안정적입니다.
컨텍스트 관리하기
에이전트가 코드 작성 비중을 가져갈수록, 사용자의 역할은 “직접 구현”에서 “필요한 컨텍스트 제공”으로 이동합니다. 에이전트는 결국 주어진 정보로만 판단하고 움직이기 때문에, 컨텍스트를 어떻게 주느냐가 성공률에 직결됩니다. 좋은 프롬프트란 긴 설명이 아니라, 작업에 필요한 맥락이 빠짐없이 담긴 지시입니다.
여기서 중요한 요령은 “내가 아는 것만 넣기”입니다. 실제로는 모르는 파일을 억지로 붙이는 순간, 에이전트가 중요도를 잘못 이해해 오히려 돌아가기도 합니다. 정확한 파일을 알고 있으면 태그하고, 모르면 에이전트가 찾게 두는 방식이 대부분 더 낫습니다.
에이전트가 컨텍스트를 찾게 두기
Cursor의 에이전트는 강력한 검색 도구를 갖고 있어, 사용자가 모든 파일을 수동으로 태그하지 않아도 됩니다. “인증 흐름(authentication flow)”처럼 개념으로 물어도 grep과 시맨틱 검색을 통해 관련 파일을 찾아가며 맥락을 구성합니다.
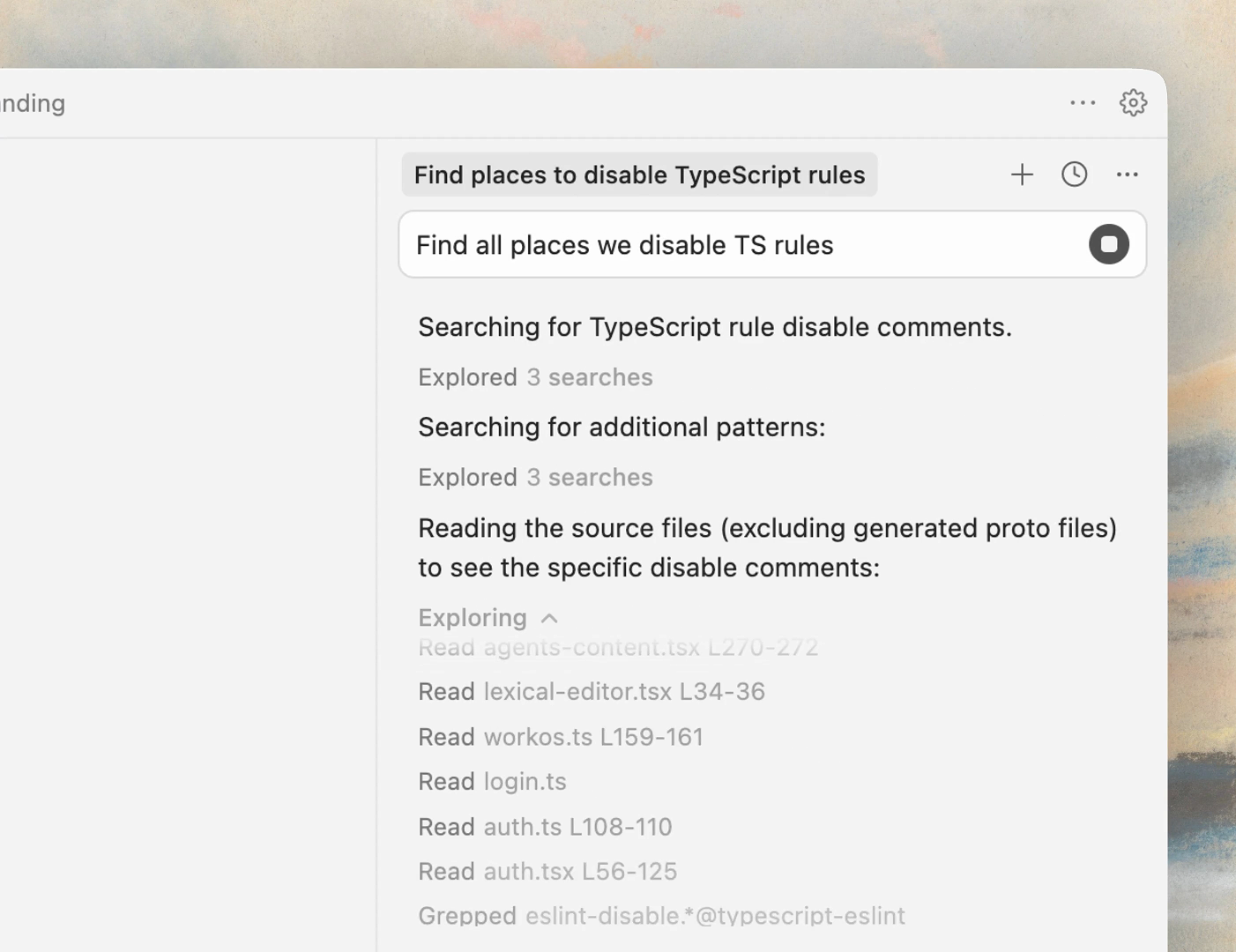
Instant grep: 코드베이스를 빠르게 검색하는 화면 (출처 : Cursor, 2026)
또한 @Branch 같은 도구를 사용하면, 현재 작업 브랜치의 맥락을 에이전트에게 자연스럽게 전달할 수 있습니다. “이 브랜치 변경사항을 리뷰해줘” 또는 “내가 지금 뭘 작업 중이야?” 같은 질문이 성립하고, 에이전트가 작업 좌표를 잃지 않게 도와줍니다. 브랜치 단위로 맥락을 잡아주는 습관은 작은 노력 대비 효과가 큽니다.
새 대화를 시작해야 할 때
“이 대화를 계속 이어갈까요, 새로 시작할까요?”는 자주 나오는 질문입니다. 기준은 의외로 단순합니다. 대화가 길어질수록 컨텍스트가 누적되고 노이즈가 늘어나며, 에이전트가 산만해질 가능성이 커집니다.
새 대화를 시작하는 편이 좋은 경우는 다음과 같습니다.
- 다른 작업이나 다른 기능으로 넘어갈 때
- 에이전트가 혼란스러워 보이거나 같은 실수를 반복할 때
- 하나의 논리적 작업 단위를 끝냈을 때
반대로 대화를 이어가는 편이 좋은 경우도 있습니다. 같은 기능을 계속 다듬는 중이거나, 앞선 논의의 맥락이 디버깅에 꼭 필요할 때가 그렇습니다. 효과가 떨어진다는 느낌이 들면 리셋이 답인 경우가 많고, 그 타이밍을 놓치지 않는 것이 중요합니다.
과거 작업 참고하기
새 대화를 열 때는 이전 대화를 통째로 복사해 붙이는 방식보다 @Past Chats로 참조하는 편이 효율적입니다. 에이전트는 과거 대화에서 필요한 부분만 선택적으로 읽어올 수 있어, 컨텍스트 윈도우를 덜 쓰면서도 핵심 맥락을 유지할 수 있습니다.
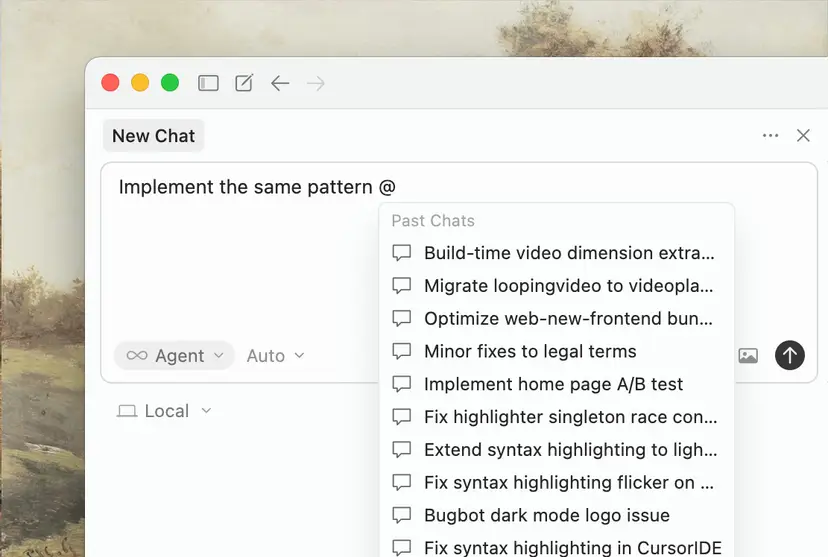
Past Chats를 참조해 이전 대화에서 필요한 맥락을 가져오는 화면 (출처 : Cursor, 2026)
중복을 줄이는 것이 곧 품질을 올리는 길이기도 합니다.
불필요한 대화 로그를 계속 누적시키면, 중요한 신호가 묻히고 에이전트가 잘못된 방향으로 확신을 쌓을 수 있습니다.
에이전트 확장하기
Cursor는 에이전트의 동작을 커스터마이징하는 방법을 두 가지 축으로 제공합니다. 하나는 모든 대화에 상시 적용되는 Rules이고, 다른 하나는 필요할 때만 로드되는 Skills입니다. 둘의 차이는 “항상 들고 다니는 규칙”과 “상황에 따라 꺼내 쓰는 능력”이라고 보면 이해가 쉽습니다.
Rules: 프로젝트에 항상 적용되는 정적 컨텍스트
Rules는 프로젝트에서 에이전트가 따라야 할 기본 지침을 “항상 켜진 상태”로 제공하는 장치입니다. .cursor/rules/ 아래에 Markdown 파일로 작성할 수 있고, 보통은 자주 쓰는 명령어, 코드 스타일, 작업 흐름의 핵심을 담습니다.
예시는 아래와 같습니다.
# Commands
-`npm run build`: Build the project
-`npm run typecheck`: Run the typechecker
-`npm run test`: Run tests (prefer single test files for speed)
# Code style
- Use ES modules (import/export), not CommonJS (require)
- Destructure imports when possible:`import { foo } from 'bar'`
- See`components/Button.tsx` for canonical component structure
# Workflow
- Always typecheck after making a series of code changes
- API routes go in`app/api/` following existing patterns
Rules는 짧고 핵심적일수록 좋습니다. 스타일 가이드를 통째로 복사해 넣는 대신 린터를 쓰는 편이 낫고, 모든 명령을 나열하기보다 “이 프로젝트에서 중요한 것만” 남기는 편이 유지보수에 유리합니다. 특히 코드가 바뀌면 규칙도 금방 낡기 때문에, 내용 복사보다 파일 참조를 우선하는 습관이 안전합니다.
피해야 할 패턴도 명확합니다.
- 스타일 가이드를 통째로 Rules에 붙여 넣기(린터가 더 적합합니다)
- 가능한 모든 명령을 문서화하기(에이전트는 흔한 도구를 압니다)
- 거의 발생하지 않는 엣지 케이스까지 규칙으로 강제하기
Rules는 git에 커밋해 팀 전체가 함께 쓰는 편이 좋습니다. 같은 실수가 반복되면 Rules를 업데이트하고, 필요하다면 GitHub 이슈나 PR에서 @cursor를 태그해 규칙 갱신을 돕는 방식도 사용할 수 있습니다. Rule은 “처음부터 완벽하게”가 아니라 “반복되는 문제를 줄이는 방향으로” 점진적으로 다듬는 것이 현실적입니다.
Skills: 필요할 때 불러오는 동적 기능과 워크플로우
Skills는 에이전트의 능력을 확장하는 패키지입니다. SKILL.md 파일로 정의하며, 에이전트가 “관련성이 있다”고 판단할 때만 동적으로 로드됩니다. 이 덕분에 컨텍스트를 상시로 무겁게 만들지 않으면서도, 특정 작업에 필요한 전문 워크플로우를 제공할 수 있습니다.
Skills에 포함될 수 있는 요소는 대표적으로 다음과 같습니다.
/로 호출하는 커스텀 커맨드(반복 가능한 워크플로우)- 에이전트 행동 전후로 실행되는 훅(Hooks)
- 특정 작업에 필요한 도메인 지식(필요 시 온디맨드로 로드)
상시 규칙은 얇게 유지하고, 특수한 작업 능력은 Skills로 분리하는 편이 대개 더 깔끔한 운영 방식입니다. Rules가 많아질수록 컨텍스트가 오염될 위험이 커지기 때문입니다.
예시: 오래 도는 에이전트 루프(장시간 반복 패턴)
Skills를 활용하면 목표를 달성할 때까지 에이전트를 반복 실행시키는 패턴을 만들 수 있습니다. 예를 들어 “테스트가 모두 통과할 때까지 실행하고 수정하기” 같은 작업이 여기에 해당합니다.
먼저 .cursor/hooks.json에 훅을 설정합니다.
{
"version":1,
"hooks":{
"stop":[{"command":"bun run .cursor/hooks/grind.ts"}]
}
}
다음으로 훅 스크립트(.cursor/hooks/grind.ts)는 stdin으로 전달된 컨텍스트를 읽고, 루프를 이어갈 followup_message를 반환할 수 있습니다.
import { readFileSync, existsSync }from"fs";
interfaceStopHookInput {
conversation_id:string;
status:"completed" |"aborted" |"error";
loop_count:number;
}
constinput:StopHookInput =awaitBun.stdin.json();
constMAX_ITERATIONS =5;
if (input.status !=="completed" || input.loop_count >=MAX_ITERATIONS) {
console.log(JSON.stringify({}));
process.exit(0);
}
const scratchpad =existsSync(".cursor/scratchpad.md")
?readFileSync(".cursor/scratchpad.md","utf-8")
:"";
if (scratchpad.includes("DONE")) {
console.log(JSON.stringify({}));
}else {
console.log(JSON.stringify({
followup_message:`[Iteration ${input.loop_count + 1}/${MAX_ITERATIONS}] Continue working. Update .cursor/scratchpad.md with DONE when complete.`
}));
}
이 방식은 “성공 여부를 확인할 수 있는 목표”에 특히 잘 맞습니다. 테스트 통과, UI 목업 일치처럼 검증 가능한 신호가 있으면, 에이전트는 변경→평가→개선을 빠르게 반복할 수 있습니다. 훅 기반 Skills는 보안 도구, 시크릿 매니저, 관측(Observability) 플랫폼과의 통합도 가능하며, 파트너 연동 사례는 Hooks 문서에서 확인할 수 있습니다.
참고로 Agent Skills는 현재 Nightly 릴리즈 채널에서만 제공됩니다. Cursor 설정에서 Beta를 선택한 뒤 업데이트 채널을 Nightly로 변경하고 재시작하면 사용할 수 있습니다. MCP(Model Context Protocol)를 통해 Slack, Datadog, Sentry, DB 같은 외부 도구와 연결해 에이전트의 활용 범위를 넓히는 것도 가능합니다.
이미지 포함하기
에이전트는 프롬프트에 포함된 이미지를 직접 처리할 수 있습니다. 스크린샷을 붙여 넣거나 디자인 파일을 드래그해 넣거나, 이미지 경로를 참조하는 방식이 모두 가능합니다. 텍스트로 길게 설명하는 대신, 이미지 한 장으로 정확한 맥락을 전달하는 편이 더 빠르고 정확할 때가 많습니다.
디자인을 코드로
디자인 목업을 붙여 넣고 구현을 요청하면, 에이전트는 레이아웃, 색상, 간격을 맞추는 작업을 도와줄 수 있습니다. Figma MCP 서버를 활용하는 방식도 소개되어 있습니다.
시각적 디버깅
오류 상태나 기대와 다른 UI를 스크린샷으로 보여주고 원인을 조사하게 하면, 말로 설명하는 시간을 크게 줄일 수 있습니다. 에이전트가 브라우저를 제어해 직접 스크린샷을 찍고 애플리케이션을 테스트하며 시각적 변경을 검증하는 기능도 제공됩니다.
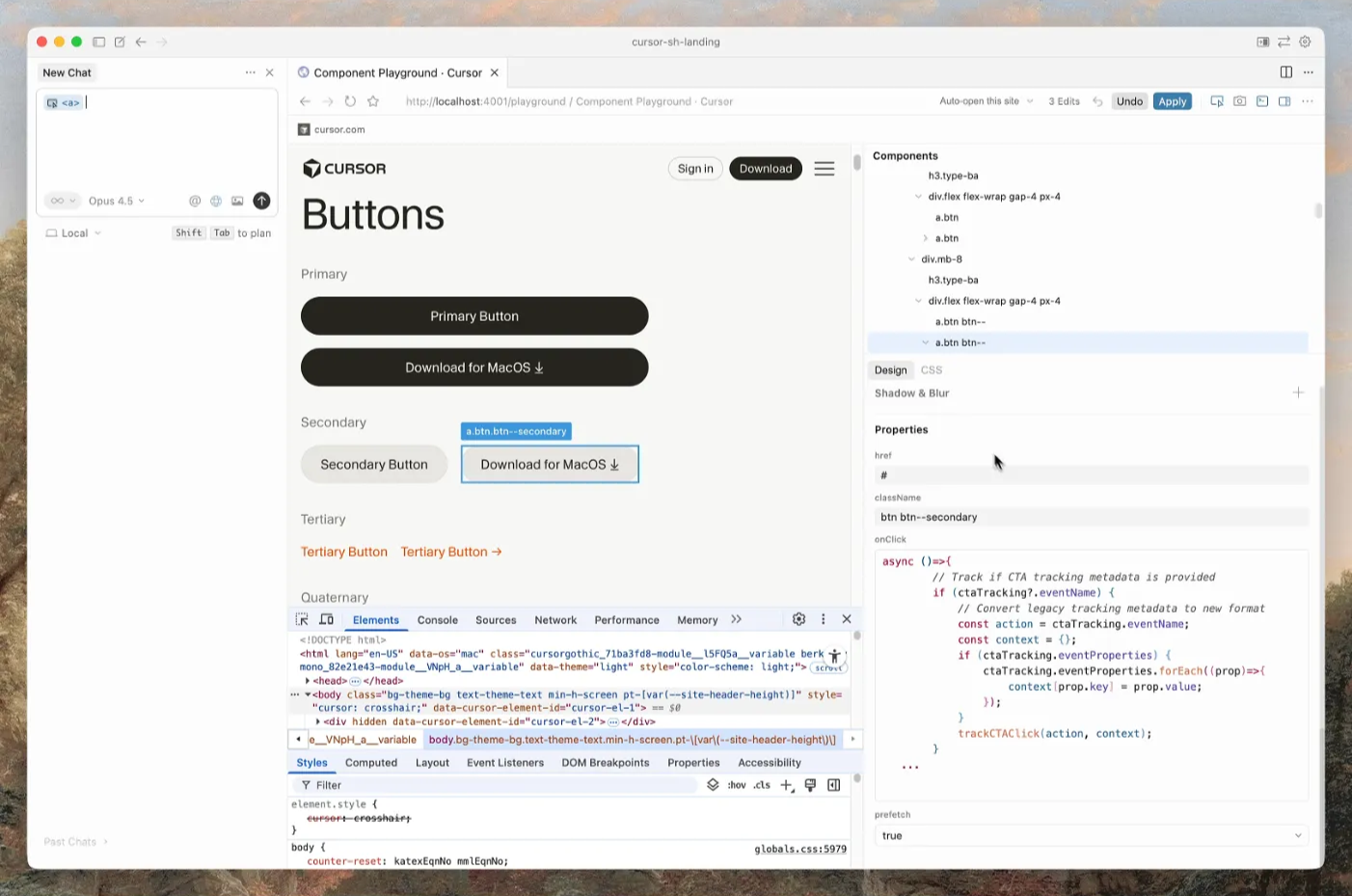
브라우저 사이드바: 디자인과 코딩을 나란히 놓고 진행하는 화면 (출처 : Cursor, 2026)
자주 쓰는 워크플로우
다음은 작업 유형을 가리지 않고 자주 통하는 에이전트 패턴들입니다. 팀의 기본 습관으로 정착시키기에도 좋고, 개인이 쓰기에도 부담이 크지 않습니다. 중요한 건 “일을 잘게 쪼개는 것”이 아니라, “검증 가능한 목표를 만드는 것”입니다.
테스트 주도 개발(TDD)
에이전트는 테스트 작성, 실행, 반복 개선을 빠르게 수행할 수 있습니다. 다만 TDD에서는 단계별로 “하지 말아야 할 일”을 명확히 지정하는 것이 중요합니다.
- 기대 입력/출력 쌍을 바탕으로 테스트를 먼저 작성하게 합니다.
- TDD임을 분명히 밝혀, 아직 없는 기능을 임시 구현(mock)으로 만들지 않게 합니다.
- 테스트를 실행해 실패하는지 확인하되, 이 단계에서는 구현 코드를 쓰지 말라고 지시합니다.
- 테스트가 만족스러우면 테스트를 커밋합니다.
- 구현은 테스트를 수정하지 말라는 조건으로 진행시키고, 모든 테스트가 통과할 때까지 반복하게 합니다.
테스트는 에이전트에게 가장 명확한 “정답 판별 장치”를 제공하며, 이 신호가 있을 때 반복 루프의 품질이 크게 올라갑니다. 구현이 빠를수록 리뷰의 중요도도 같이 올라가니, diff 단위로 꼼꼼히 확인하는 습관이 필요합니다.
코드베이스 이해
새 코드베이스에 적응할 때 에이전트는 특히 강력합니다. 동료에게 묻듯이 질문하면, 에이전트는 grep과 시맨틱 검색을 통해 근거가 되는 파일과 라인을 찾아 설명해 줍니다. 예를 들면 아래와 같은 질문이 가능합니다.
- “이 프로젝트에서 로깅은 어떻게 동작하나요?”
- “새 API 엔드포인트는 어떤 방식으로 추가하나요?”
- “CustomerOnboardingFlow는 어떤 엣지 케이스를 처리하나요?”
- “1738번째 줄에서 createUser()가 아니라 setUser()를 호출하는 이유가 뭔가요?”
온보딩 초기에 “검색과 이해”에 드는 비용을 줄이면, 팀의 전체 속도가 빠르게 올라갑니다. 특히 레거시 코드나 도메인 지식이 두꺼운 프로젝트에서는 효과가 더 큽니다.
Git 워크플로우
에이전트는 git 히스토리 검색, 머지 컨플릭트 해결, 반복적인 Git 작업 자동화에도 쓸 수 있습니다. 예를 들어 /pr 커맨드처럼 커밋과 푸시, PR 오픈까지의 과정을 하나의 명령으로 묶는 식입니다.
“현재 변경사항으로 Pull Request를 생성해줘.
git diff로 staged/unstaged 변경을 확인한다- 변경사항을 바탕으로 커밋 메시지를 작성한다
- 커밋하고 현재 브랜치에 푸시한다
gh pr create로 제목/설명을 포함한 PR을 생성한다- PR URL을 반환한다”
이런 커맨드는 .cursor/commands/에 저장해두고 팀에서 공유할 수 있습니다. /fix-issue, /review, /update-deps처럼 반복 작업을 표준화한 커맨드도 실무에서 자주 쓰입니다. 반복 업무를 한 줄 호출로 바꾸는 순간, 에이전트의 가치는 가장 빠르게 체감됩니다.
코드 리뷰하기
AI가 만든 코드는 반드시 리뷰가 필요합니다. Cursor는 생성 중과 생성 후를 나눠, 리뷰에 필요한 흐름을 여러 형태로 제공합니다. 빠르게 만든 코드일수록 “그럴듯한 오답”이 섞일 수 있다는 전제를 놓치면 안 됩니다.
생성 중 리뷰
에이전트가 작업하는 동안 diff 뷰에서 변경 사항이 실시간으로 쌓이는 것을 볼 수 있습니다. 방향이 어긋났다고 느껴지면 Escape로 중단하고 즉시 재지시할 수 있습니다.
Agent Review
작업이 끝난 뒤 Review → Find Issues로 별도의 리뷰 패스를 돌릴 수 있습니다. 라인 단위로 변경을 분석해 잠재 문제를 표시해 주며, Source Control 탭에서 메인 브랜치와 비교하는 방식으로 로컬 변경 전체를 점검할 수도 있습니다.
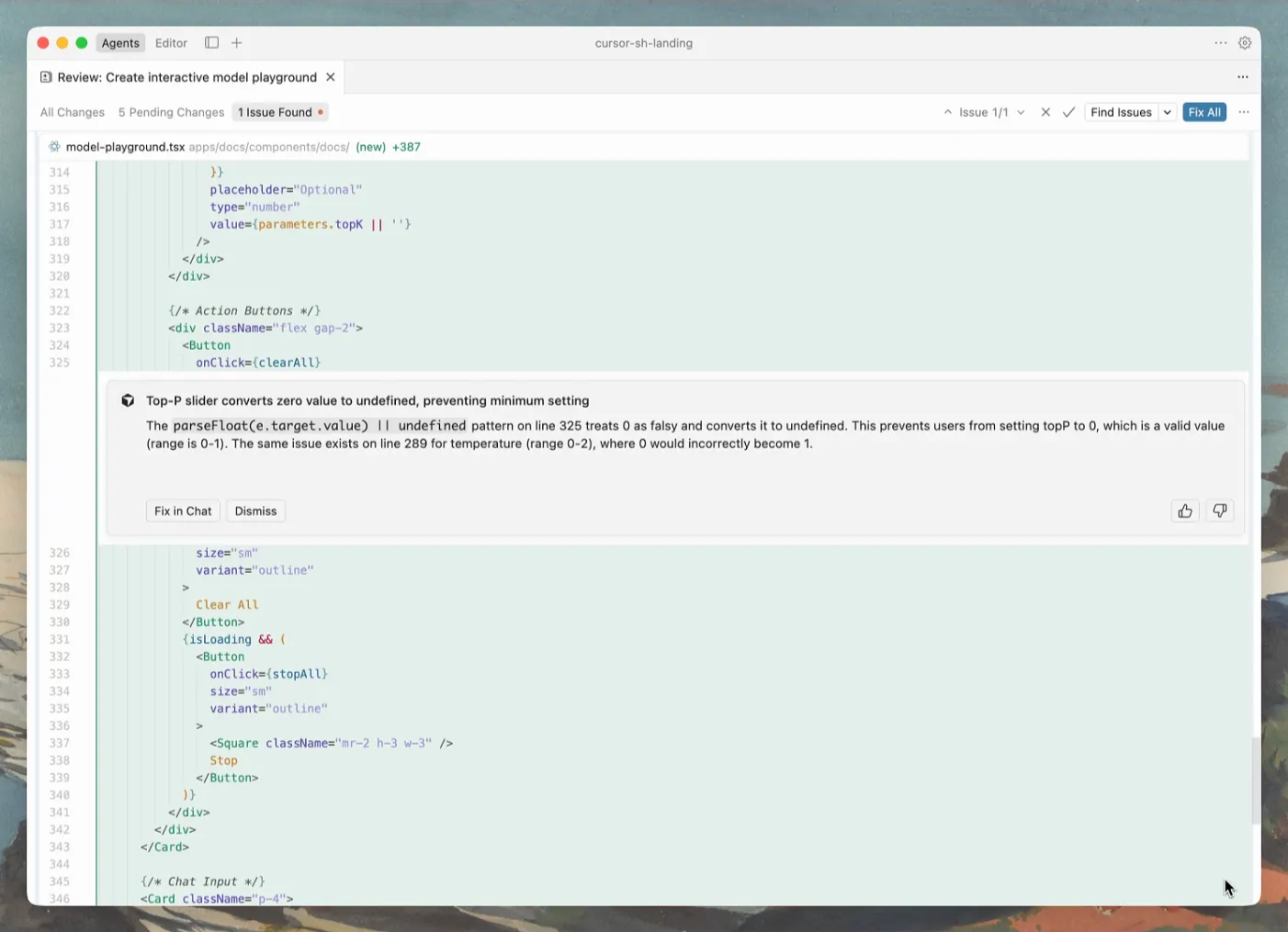
Agent Review: 변경을 분석하고 문제를 잡아내는 화면 (출처 : Cursor, 2026)
PR용 Bugbot
원격 저장소에 푸시하면 PR에서 자동 리뷰를 받을 수 있습니다. Bugbot은 PR마다 고급 분석을 수행해 문제를 조기에 잡고 개선 제안을 남깁니다.
아키텍처 다이어그램
의미 있는 변경이 있을 때는 Mermaid 다이어그램 같은 아키텍처 시각화를 요청하는 것도 유용합니다. OAuth 제공자, 세션 관리, 토큰 리프레시를 포함한 인증 시스템의 데이터 흐름을 다이어그램으로 그리게 하면, 구조적 문제를 코드 리뷰 이전에 발견할 수 있습니다. 복잡한 변경일수록 “그림으로 먼저 검증”하는 방식이 실수를 줄입니다.
병렬로 에이전트 돌리기
어려운 문제일수록 한 번에 정답을 내기보다, 여러 에이전트를 병렬로 돌려 가장 나은 결과를 선택하는 방식이 효과적입니다. Cursor는 이를 쉽게 하기 위해 병렬 실행을 지원하고, 에이전트끼리 서로 충돌하지 않도록 격리 환경을 제공합니다. 동일한 문제를 여러 모델에 던져 비교하면, 최종 결과의 품질이 유의미하게 좋아지는 경우가 많습니다.
워크트리(worktree) 네이티브 지원
Cursor는 병렬 에이전트를 위해 git worktree를 자동으로 생성하고 관리합니다. 각 에이전트는 독립된 worktree에서 실행되므로 파일 변경이 충돌하지 않고, 각자 빌드와 테스트도 안전하게 수행할 수 있습니다. 에이전트 드롭다운에서 worktree 옵션을 선택해 실행하고, 완료 후 Apply로 변경 사항을 현재 브랜치에 합칠 수 있습니다.
여러 모델을 동시에 실행하기
같은 프롬프트를 여러 모델에 동시에 던져 결과를 비교하는 패턴도 강력합니다. 드롭다운에서 여러 모델을 선택해 실행하면, 결과가 나란히 표시되고 Cursor가 “가장 좋아 보이는 해법”을 추천하기도 합니다.
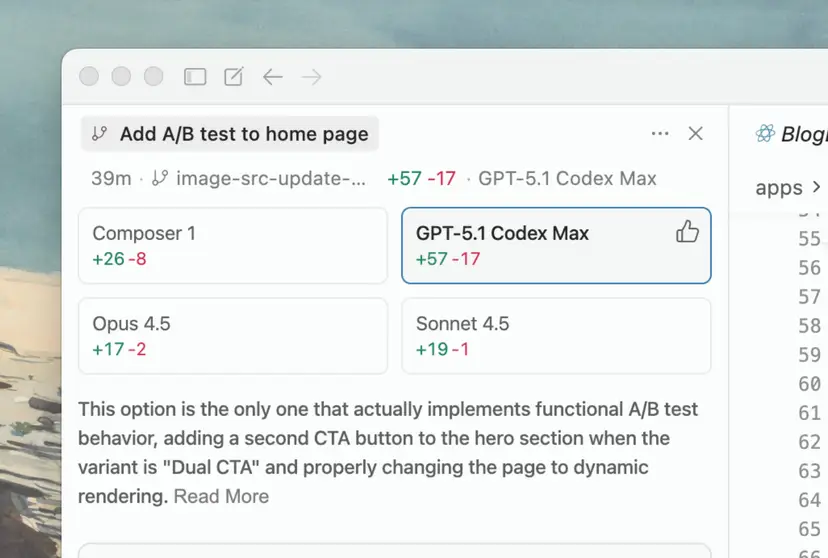
Multi-agent judging: 여러 모델 결과를 비교하고 Cursor가 추천하는 화면 (출처 : Cursor, 2026)
이 방식은 특히 아래 상황에서 유용합니다.
- 모델마다 접근이 갈릴 수 있는 난이도 높은 문제
- 모델 패밀리별 코드 품질 비교
- 한 모델이 놓치기 쉬운 엣지 케이스 탐색
병렬 실행을 많이 한다면, 완료 알림과 소리 설정을 켜서 종료 시점을 놓치지 않게 구성하는 것도 도움이 됩니다.
클라우드 에이전트에 위임하기
클라우드 에이전트는 “당장 집중하기 어려운 작업”을 백로그처럼 맡기기에 좋습니다. 버그 픽스, 리팩터링, 테스트 생성, 문서 업데이트처럼 손이 많이 가지만 미뤄두기 쉬운 일을 위임할 수 있습니다. 로컬과 클라우드를 작업 성격에 따라 나눠 쓰면, 집중해야 할 본 작업의 흐름이 덜 끊깁니다.
클라우드 에이전트는 cursor.com/agents, Cursor 에디터, 휴대폰에서도 시작할 수 있고, 웹이나 모바일에서 세션 진행 상황을 확인할 수 있습니다. 원격 샌드박스에서 실행되므로 노트북을 닫아도 작업은 이어집니다.
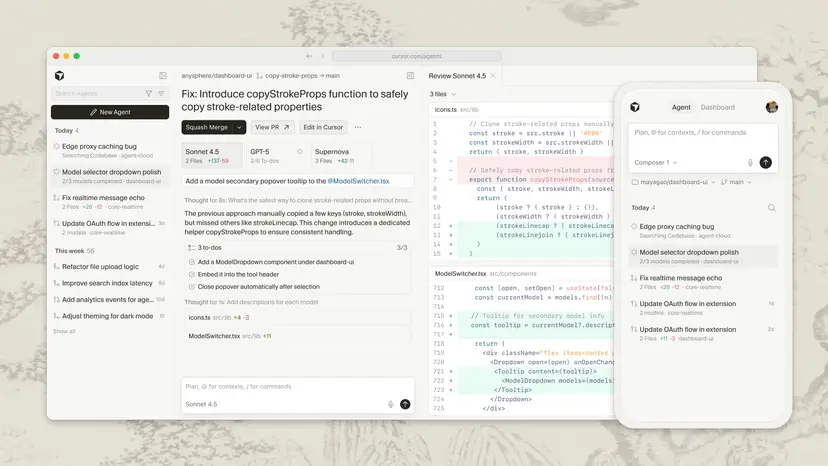
Cursor Agents를 칸반 형태로 관리하는 화면(코딩/리서치 세션 포함) (출처 : Cursor, 2026)
클라우드 에이전트가 내부적으로 수행하는 흐름은 다음과 같습니다.
- 작업과 필요한 컨텍스트를 입력합니다.
- 에이전트가 레포를 클론하고 브랜치를 생성합니다.
- 에이전트가 자율적으로 작업하고 PR을 엽니다.
- 완료되면 Slack, 이메일, 웹 알림으로 알려줍니다.
- 사용자는 변경을 리뷰하고 머지합니다.
Slack에서 “@Cursor”로 에이전트를 트리거하는 방식도 지원됩니다.
난이도 높은 버그를 위한 Debug Mode
표준적인 에이전트 상호작용으로 해결이 잘 안 되는 버그가 있습니다. Debug Mode는 이런 상황에서 “추측”이 아니라 “증거”로 접근하는 흐름을 제공합니다. 원인을 모른 채 수정안을 찍어보는 대신, 실제 동작 데이터를 모아 원인을 좁히는 방식입니다.
Debug Mode에서는 보통 아래 단계를 거칩니다. 여러 가설을 만들고, 로그 등 계측(instrumentation)을 추가하며, 사용자가 버그를 재현하도록 요청해 런타임 데이터를 수집합니다. 그 데이터를 분석해 근본 원인을 찾아낸 뒤, 필요한 부분만 타깃으로 수정합니다.
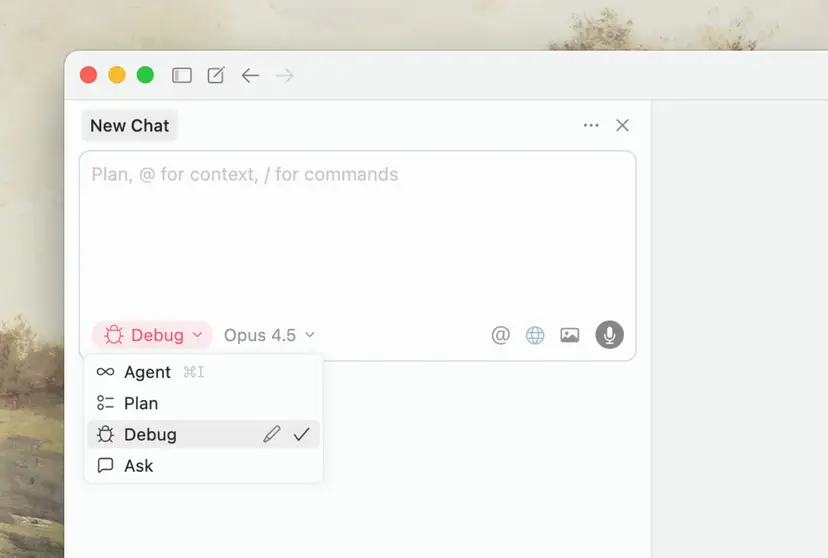
에이전트 드롭다운에서 Debug Mode를 선택하는 화면 (출처 : Cursor, 2026)
Debug Mode가 특히 잘 맞는 상황은 재현은 되지만 원인을 모르겠는 버그, 레이스 컨디션과 타이밍 이슈, 성능 문제나 메모리 누수, 회귀(regression)입니다.
재현 방법을 구체적으로 제공할수록, 에이전트가 추가하는 계측의 질도 높아지고 분석도 빨라집니다. Debug Mode는 설명보다 재현과 데이터가 중심입니다.
워크플로우를 발전시키기
에이전트를 가장 잘 활용하는 개발자들은 공통된 습관이 있습니다. 프롬프트를 구체적으로 쓰고, 반복되는 문제를 관찰하며 규칙과 커맨드를 점진적
에이전트는 “무엇이 성공인지”를 알 때 가장 강해지며, 타입 시스템·린터·테스트는 그 성공 신호를 제공하는 장치입니다. 계획을 요청하고, 설명을 요구하고, 마음에 들지 않는 접근에는 반박하며, 협업자로 대하는 태도도 결과를 바꿉니다.
에이전트는 계속 좋아지고 있고, 그에 따라 패턴도 진화할 것입니다. 그럼에도 오늘 당장 생산성을 끌어올리는 방법은 비교적 명확합니다. Plan Mode로 의도를 고정하고, 컨텍스트는 필요한 만큼만 제공하며, 검증 가능한 목표를 세우는 것부터 시작해 보세요.
마무리: 다음 단계로 넘어가기 전에
리트머스는 AI·바이브코딩 기반 실전 외주개발을 “운영 가능한 프로세스”로 만드는 팀입니다. 단순히 코드를 빨리 뽑는 데서 끝내지 않고, 계획–검증(–리뷰–반복 루프를 기본값으로 두고 속도와 정확도를 함께 끌어올립니다. 요구사항이 흔들리는 구간에서는 기획 관점에서 기능 범위를 재정리하고, 보안·품질 리스크는 체크리스트와 자동화된 검증 루틴으로 선제적으로 잡아드립니다. 무료 견적 상담을 요청하시면 바로 안내드리겠습니다. “우리 프로젝트가 바이브코딩 외주에 적합한지 검토해드립니다.”
그런데 여기서 한 가지가 더 남습니다. 에이전트를 도입해 생산성을 끌어올리는 것과 별개로, 어떤 조건을 갖춰야 ‘안전하게’ 맡기고, 어떤 경우에는 애초에 방식부터 바꿔야 하는지가 다음 고민으로 이어지죠.
AI 코딩 외주, 이 체크리스트 안 보고 맡기면 100% 후회합니다
이 글은 에이전트 활용이 실제 프로젝트로 들어갔을 때 가장 자주 터지는 문제—명세 누락, 품질 검증 부재, 보안 점검 공백, 운영/인수인계 실패—를 “사전에 확인할 질문”으로 바꿔 정리해 둔 안내서입니다. 지금 글에서 다룬 계획·컨텍스트·검증 루프를 외주 의사결정의 체크리스트로 전환해 주기 때문에, “우리 팀은 어디까지 맡길 수 있는지” 판단 기준을 세우는 데 도움이 됩니다.
무료 견적 상담을 통해 우리 프로젝트가 어디까지 가능한지 확인해 보셔도 좋습니다!
이 글은 Cursor 공식 블로그 가이드 「Best practices for coding with agents」(2026.01.09)를 바탕으로, 핵심 흐름과 실무 팁을 한국어로 정리한 내용입니다.







![[2026년 4월 최신] 오픈클로 완벽 가이드: 뜻, PC 설치 방법부터 실무 활용 사례까지](/_next/image?url=https%3A%2F%2Fuosmtaxndlzgvsnhbugi.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fmedia%2Ffile-18.png&w=3840&q=75)